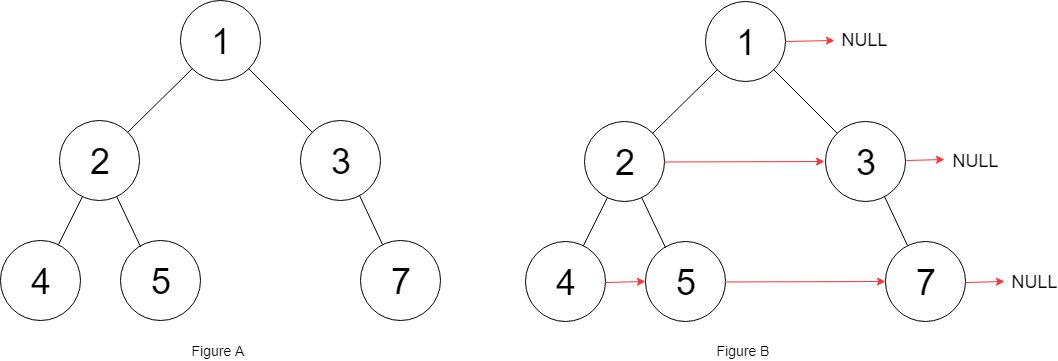
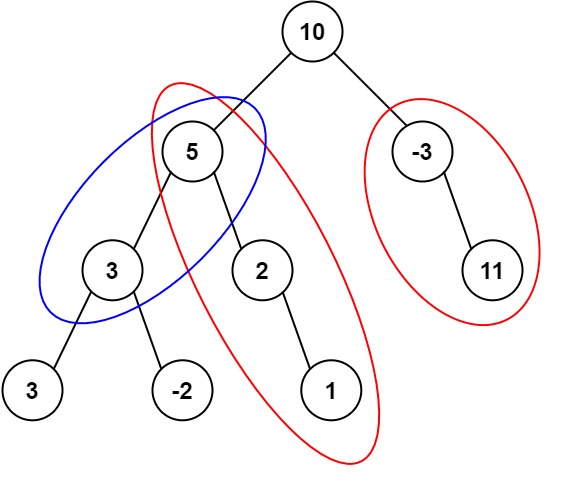
Trivia: This problem was inspired by this original tweet by Max Howell: Google: 90% of our engineers use the software you wrote (Homebrew), but you can’t invert a binary tree on a whiteboard so f*** off.
Given two binary trees, write a function to check if they are the same or not. Two binary trees are considered the same if they are structurally identical and the nodes have the same value.
Given a binary tree, check whether it is a mirror of itself (ie, symmetric around its center).
1 2 3 4 5 6 7 8 9 10 11 12
For example, this binary tree [1,2,2,3,4,4,3] is symmetric: 1 / \ 2 2 / \ / \ 3 4 4 3 But the following [1,2,2,null,3,null,3] is not: 1 / \ 2 2 \ \ 3 3
Note: Bonus points if you could solve it both recursively and iteratively.
递归
1 2 3 4 5 6 7 8 9
classSolution: defisSymmetric(self, root: TreeNode) -> bool: defhelper(l, r): ifnot l andnot r: returnTrue if (l andnot r) or (not l and r): returnFalse return l.val == r.val and helper(l.left, r.right) and helper(l.right, r.left) return helper(root.left, root.right)
遍历:
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: defisSymmetric(self, root: Optional[TreeNode]) -> bool: stack = [(root.left, root.right)] while stack: (l, r) = stack.pop() ifnot l andnot r: continue if l andnot r ornot l and r or l.val != r.val: returnFalse if l and r: stack.append((l.left, r.right)) stack.append((l.right, r.left)) returnTrue
Given a binary tree, find its maximum depth. The maximum depth is the number of nodes along the longest path from the root node down to the farthest leaf node. Note: A leaf is a node with no children.
1 2 3 4 5 6 7 8
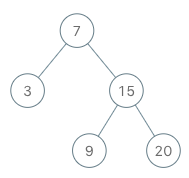
Example: Given binary tree [3,9,20,null,null,15,7], 3 / \ 9 20 / \ 15 7 return its depth = 3.
递归1:
1 2 3 4 5 6 7 8 9 10 11
classSolution: defmaxDepth(self, root: Optional[TreeNode]) -> int: defhelper(root, depth = 0): nonlocal ans ans = max(ans, depth) if root: helper(root.left, depth + 1) helper(root.right, depth + 1) ans = 0 helper(root) return ans
classSolution: defmaxDepth(self, root: Optional[TreeNode]) -> int: ifnot root: return0 ans = 0 stack = [(root, 1)] while stack: root, cur = stack.pop() ans = max(ans, cur) if root.left: stack.append((root.left, cur + 1)) if root.right: stack.append((root.right, cur + 1)) return ans
遍历2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution: defmaxDepth(self, root: Optional[TreeNode]) -> int: q = [[root]] ans = 0 while q: cur = [] for root in q.pop(0): if root: cur.append(root.left) cur.append(root.right) if cur: ans += 1 q.append(cur) return ans
again! 递归,遍历已掌握 Given a binary tree, find its minimum depth. The minimum depth is the number of nodes along the shortest path from the root node down to the nearest leaf node. Note: A leaf is a node with no children. Example:
1 2 3 4 5 6 7
Given binary tree [3,9,20,null,null,15,7], 3 / \ 9 20 / \ 15 7 return its minimum depth = 2.
遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defminDepth(self, root: Optional[TreeNode]) -> int: ifnot root: return0 stack = [(root, 1)] ans = sys.maxsize while stack: root, depth = stack.pop() ifnot root.left andnot root.right: ans = min(ans, depth) if root.left: stack.append((root.left, depth + 1)) if root.right: stack.append((root.right, depth + 1)) return ans
递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defminDepth(self, root: TreeNode) -> int: ifnot root: return0 ans = sys.maxsize defhelper(root, cur): nonlocal ans ifnot root: return ifnot root.left andnot root.right: ans = min(ans, cur) helper(root.left, cur + 1) helper(root.right, cur + 1) helper(root, 1) return ans
again! Given a binary tree, return the preorder traversal of its nodes’ values.
1 2 3 4 5 6 7 8 9
Example: Input: [1,null,2,3] 1 \ 2 / 3
Output: [1,2,3]
Follow up: Recursive solution is trivial, could you do it iteratively?
递归 Divide and Conquer 分治 / backtracking:
1 2 3 4 5 6 7
classSolution: defpreorderTraversal(self, root): ifnot root: return [] l = self.preorderTraversal(root.left) r = self.preorderTraversal(root.right) return [root.val] + l + r
遍历:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defpreorderTraversal(self, root): ifnot root: return [] ans = [] stack = [] while stack or root: if root: ans.append(root.val) if root.right: stack.append(root.right) root = root.left else: root = stack.pop(-1) return ans
递归 Traverse:
1 2 3 4 5 6 7 8 9 10 11
classSolution: defpreorderTraversal(self, root): ans = [] defhelper(root): ifnot root: return ans.append(root.val) helper(root.left) helper(root.right) helper(root) return ans
Given a binary tree, return the inorder traversal of its nodes’ values. Example:
1 2 3 4 5 6 7 8
Input: [1,null,2,3] 1 \ 2 / 3
Output: [1,3,2]
Follow up: Recursive solution is trivial, could you do it iteratively?
递归 Traverse:
1 2 3 4 5 6 7 8 9 10 11
classSolution: definorderTraversal(self, root): ans = [] defhelper(root): ifnot root: return helper(root.left) ans.append(root.val) helper(root.right) helper(root) return ans
遍历:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: definorderTraversal(self, root): ifnot root: return [] ans = [] stack = [] while stack or root: if root: stack.append(root) root = root.left else: root = stack.pop(-1) ans.append(root.val) root = root.right return ans
递归 Divide and Conquer/backtracking 分治:
1 2 3 4 5 6 7
classSolution: definorderTraversal(self, root): ifnot root: return [] l = self.inorderTraversal(root.left) r = self.inorderTraversal(root.right) return l + [root.val] + r
八刷:高频, 遍历,stack初始为空,while root or stack: if root: 向左入栈到底 else: root出栈,root.val入ans,向右走…root = root.right
Given a binary search tree, write a function kthSmallest to find the kth smallest element in it. Note: You may assume k is always valid, 1 ≤ k ≤ BST’s total elements.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
Example 1: Input: root = [3,1,4,null,2], k = 1 3 / \ 1 4 \ 2 Output: 1
Follow up: What if the BST is modified (insert/delete operations) often and you need to find the kth smallest frequently? How would you optimize the kthSmallest routine?
递归:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defkthSmallest(self, root: TreeNode, k: int) -> int: ans = None defhelper(root): nonlocal k, ans ifnot root: return helper(root.left) k -= 1 if k == 0: ans = root.val return helper(root.right) helper(root) return ans
遍历:
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: defkthSmallest(self, root: TreeNode, k: int) -> int: stack = [] while stack or root: if root: stack.append(root) root = root.left else: root = stack.pop() k -= 1 if k == 0: return root.val root = root.right
again! Given a binary tree containing digits from 0-9 only, each root-to-leaf path could represent a number. An example is the root-to-leaf path 1->2->3 which represents the number 123. Find the total sum of all root-to-leaf numbers. Note: A leaf is a node with no children.
Example: Input: [1,2,3] 1 / \ 2 3 Output: 25 Explanation: The root-to-leaf path 1->2 represents the number 12. The root-to-leaf path 1->3 represents the number 13. Therefore, sum = 12 + 13 = 25.
Example 2: Input: [4,9,0,5,1] 4 / \ 9 0 / \ 5 1 Output: 1026 Explanation: The root-to-leaf path 4->9->5 represents the number 495. The root-to-leaf path 4->9->1 represents the number 491. The root-to-leaf path 4->0 represents the number 40. Therefore, sum = 495 + 491 + 40 = 1026.
递归:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution: defsumNumbers(self, root: TreeNode) -> int: ifnot root: return0 ans = 0 defhelper(root, cur): nonlocal ans ifnot root: return cur += root.val ifnot root.left andnot root.right: ans += cur return helper(root.left, cur * 10) helper(root.right, cur * 10) helper(root, 0) return ans
遍历:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution: defsumNumbers(self, root: TreeNode) -> int: ifnot root: return0 ans = 0 s = [(root, 0)] while s: root, cur = s.pop(-1) if root: cur += root.val ifnot root.left andnot root.right: ans += cur continue s.append((root.left, cur * 10)) s.append((root.right, cur * 10)) return ans
You are given a perfect binary tree where all leaves are on the same level, and every parent has two children. The binary tree has the following definition:
Populate each next pointer to point to its next right node. If there is no next right node, the next pointer should be set to NULL. Initially, all next pointers are set to NULL. Example:
Populate each next pointer to point to its next right node. If there is no next right node, the next pointer should be set to NULL. Initially, all next pointers are set to NULL. Example: Note: You may only use constant extra space. Recursive approach is fine, implicit stack space does not count as extra space for this problem.
classSolution: defconnect(self, root: 'Node') -> 'Node': ifnot root: return defhelper(root): ifnot root: return if root.left: return root.left if root.right: return root.right return helper(root.next) if root.left: if root.right: root.left.next = root.right else: root.left.next = helper(root.next) if root.right: root.right.next = helper(root.next) self.connect(root.right) self.connect(root.left) return root
遍历:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution: defconnect(self, root: 'Node') -> 'Node': ifnot root: return cur = root nextLevelHead = Node(0) while cur: p = nextLevelHead while cur: if cur.left: p.next = cur.left p = p.next if cur.right: p.next = cur.right p = p.next cur = cur.next cur = nextLevelHead.next nextLevelHead.next = None return root
again! Given a binary tree, determine if it is height-balanced. For this problem, a height-balanced binary tree is defined as: a binary tree in which the depth of the two subtrees of every node never differ by more than 1.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
Example 1: Given the following tree [3,9,20,null,null,15,7]: 3 / \ 9 20 / \ 15 7 Return true.
Example 2: Given the following tree [1,2,2,3,3,null,null,4,4]: 1 / \ 2 2 / \ 3 3 / \ 4 4 Return false.
递归1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution: defisBalanced(self, root: Optional[TreeNode]) -> bool: defhelper(root): nonlocal ans ifnot root: return0 l = helper(root.left) r = helper(root.right) ifabs(l - r) > 1: ans = False returnmax(l, r) + 1 ans = True helper(root) return ans
Given an array where elements are sorted in ascending order, convert it to a height balanced BST. For this problem, a height-balanced binary tree is defined as a binary tree in which the depth of the two subtrees of every node never differ by more than 1.
Example: Given the sorted array: [-10,-3,0,5,9], One possible answer is: [0,-3,9,-10,null,5], which represents the following height balanced BST:
again! Given a singly linked list where elements are sorted in ascending order, convert it to a height balanced BST. For this problem, a height-balanced binary tree is defined as a binary tree in which the depth of the two subtrees of every node never differ by more than 1.
Example: Given the sorted linked list: [-10,-3,0,5,9], One possible answer is: [0,-3,9,-10,null,5], which represents the following height balanced BST:
classSolution: defsortedListToBST(self, head: ListNode) -> TreeNode: if h == t: return s, f = h, h while f != t and f.next != t: s = s.next f = f.next.next root = TreeNode(s.val) root.left = helper(h, s) root.right = helper(s.next, t) return root return helper(head, None)
Given a binary tree and a sum, determine if the tree has a root-to-leaf path such that adding up all the values along the path equals the given sum. Note: A leaf is a node with no children.
Example: Given the below binary tree and sum = 22,
1 2 3 4 5 6 7 8
5 / \ 4 8 / / \ 11 13 4 / \ \ 7 2 1 return true, as there exist a root-to-leaf path 5->4->11->2 which sum is 22.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution: defhasPathSum(self, root: TreeNode, sum: int) -> bool: ifnot root: returnFalse ans = False defhelper(root, cur): nonlocal ans ifnot root: return cur -= root.val ifnot root.left andnot root.right: if cur == 0: ans = True return helper(root.left, cur) helper(root.right, cur) helper(root, sum) return ans
Given a binary search tree (BST), find the lowest common ancestor (LCA) of two given nodes in the BST. According to the definition of LCA on Wikipedia: “The lowest common ancestor is defined between two nodes p and q as the lowest node in T that has both p and q as descendants (where we allow a node to be a descendant of itself).” Given binary search tree: root = [6,2,8,0,4,7,9,null,null,3,5] Example 1: Input: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8 Output: 6 Explanation: The LCA of nodes 2 and 8 is 6.
Example 2: Input: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4 Output: 2 Explanation: The LCA of nodes 2 and 4 is 2, since a node can be a descendant of itself according to the LCA definition.
Note: All of the nodes’ values will be unique. p and q are different and both values will exist in the BST.
1 2 3 4 5 6 7 8 9 10
classSolution: deflowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode': if p.val > q.val: p, q = q, p if p.val <= root.val <= q.val: return root if root.val < p.val: return self.lowestCommonAncestor(root.right, p, q) if root.val > q.val: return self.lowestCommonAncestor(root.left, p, q)
1 2 3 4 5 6 7 8 9
classSolution: deflowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode': if p.val > q.val: p, q = q, p if root.val < p.val: return self.lowestCommonAncestor(root.right, p, q) if root.val > q.val: return self.lowestCommonAncestor(root.left, p, q) return root
1 2 3 4 5 6 7
classSolution: deflowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode': if root.val < p.val and root.val < q.val: return self.lowestCommonAncestor(root.right, p, q) if root.val > p.val and root.val > q.val: return self.lowestCommonAncestor(root.left, p, q) return root
Given a binary tree, you need to compute the length of the diameter of the tree. The diameter of a binary tree is the length of the longest path between any two nodes in a tree. This path may or may not pass through the root.
1 2 3 4 5 6 7 8
Example: Given a binary tree 1 / \ 2 3 / \ 4 5 Return 3, which is the length of the path [4,2,1,3] or [5,2,1,3].
Note: The length of path between two nodes is represented by the number of edges between them.
Given a binary tree, return the tilt of the whole tree. The tilt of a tree node is defined as the absolute difference between the sum of all left subtree node values and the sum of all right subtree node values. Null node has tilt 0. The tilt of the whole tree is defined as the sum of all nodes’ tilt.
Example:
1 2 3 4 5
Input: 1 / \ 2 3 Output: 1
Explanation: Tilt of node 2 : 0 Tilt of node 3 : 0 Tilt of node 1 : |2-3| = 1 Tilt of binary tree : 0 + 0 + 1 = 1 Note: The sum of node values in any subtree won’t exceed the range of 32-bit integer. All the tilt values won’t exceed the range of 32-bit integer.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: deffindTilt(self, root: TreeNode) -> int: ifnot root: return0 ans = 0 defhelper(root): nonlocal ans ifnot root: return0 l = helper(root.left) r = helper(root.right) ans += abs(l - r) return l + r + root.val helper(root) return ans
Given a binary search tree and the lowest and highest boundaries as L and R, trim the tree so that all its elements lies in [L, R] (R >= L). You might need to change the root of the tree, so the result should return the new root of the trimmed binary search tree.
Given a binary tree, find the length of the longest path where each node in the path has the same value. This path may or may not pass through the root. The length of path between two nodes is represented by the number of edges between them.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
Example 1: Input: 5 / \ 4 5 / \ \ 1 1 5 Output: 2
Example 2: Input: 1 / \ 4 5 / \ \ 4 4 5 Output: 2
Note: The given binary tree has not more than 10000 nodes. The height of the tree is not more than 1000.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution: deflongestUnivaluePath(self, root: TreeNode) -> int: defdfs(root): nonlocal ans ifnot root: return0 l = dfs(root.left) r = dfs(root.right) lp, rp = 0, 0 if root.left and root.val == root.left.val: lp = l + 1 if root.right and root.val == root.right.val: rp = r + 1 ans = max(ans, lp + rp) returnmax(lp, rp) ans = 0 dfs(root) return ans
写法2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: deflongestUnivaluePath(self, root: TreeNode) -> int: defdfs(root, pre): nonlocal ans ifnot root: return0 l = dfs(root.left, root) r = dfs(root.right, root) ans = max(ans, l + r) if pre and pre.val == root.val: returnmax(l, r) + 1 return0 ans = 0 dfs(root, None) return ans
16刷:写法1:l, r左右各自递归后lp = rp = 0; if …: lp = l + 1…ans = max(ans, lp + rp) return max(lp, rp)。写法2:f(root, pre) 当前层无法判断是否左右子节点都相等,但是因为如果有一边子节点不相等会将l或r返回为0,那么ans = max(ans, l + r)即可获得想要的答案
Given a binary tree, flatten it to a linked list in-place.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
For example, given the following tree: 1 / \ 2 5 / \ \ 3 4 6 The flattened tree should look like: 1 \ 2 \ 3 \ 4 \ 5 \ 6
解法1:
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: defflatten(self, root: TreeNode) -> None: ifnot root: return l = self.flatten(root.left) r = self.flatten(root.right) if l: root.right = l root.left = None while l.right: l = l.right l.right = r return root
Given a binary tree, find the lowest common ancestor (LCA) of two given nodes in the tree. According to the definition of LCA on Wikipedia: “The lowest common ancestor is defined between two nodes p and q as the lowest node in T that has both p and q as descendants (where we allow a node to be a descendant of itself).” Given the following binary tree: root = [3,5,1,6,2,0,8,null,null,7,4]
Example 1: Input: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1 Output: 3 Explanation: The LCA of of nodes 5 and 1 is 3.
Example 2: Input: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4 Output: 5 Explanation: The LCA of nodes 5 and 4 is 5, since a node can be a descendant of itself according to the LCA definition.
Note: All of the nodes’ values will be unique. p and q are different and both values will exist in the binary tree.
递归:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution: deflowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode': ifnot root: return if root == p or root == q: return root l = self.lowestCommonAncestor(root.left, p, q) r = self.lowestCommonAncestor(root.right, p, q) if l and r: return root elif l: return l elif r: return r
遍历:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution: deflowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode': parent = {root: None} stack = [root] while p notin parent or q notin parent: root = stack.pop() if root.left: parent[root.left] = root stack.append(root.left) if root.right: parent[root.right] = root stack.append(root.right) ancestors = [] while p: ancestors.append(p) p = parent[p] while q notin ancestors: q = parent[q] return q
13刷:递归:注意最后返回root需要if l and r这个条件。遍历:遍历,建立parent关系,p存入ancestors,遍历p的parent入ancestors,遍历q和q的parent,在ancestors中即返回。TODO 不需要parent关系的算法
LinC 448. Inorder Successor in BST (Medium) Given a binary search tree and a node in it, find the in-order successor of that node in the BST. If the given node has no in-order successor in the tree, return null. It’s guaranteed p is one node in the given tree. (You can directly compare the memory address to find p)
1 2 3 4 5 6 7 8 9 10 11 12
Example Given tree = [2,1] and node = 1: 2 / 1 return node 2.
Given tree = [2,1,3] and node = 2: 2 / \ 1 3 return node 3.
definorderSuccessor(self, root, p): defdfs(root): nonlocal inPre, ans ifnot root: return dfs(root.left) if inPre == p: ans = root inPre = root dfs(root.right) ans, inPre = None, None dfs(root) return ans
O(n)遍历:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution: definorderSuccessor(self, root, p): pre = None stack = [] while root or stack: if root: stack.append(root) root = root.left else: root = stack.pop() if pre == p: return root pre = root root = root.right
O(n)递归2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution: definorderSuccessor(self, root, p): found = False ans = None defhelper(root): nonlocal found, ans ifnot root: return helper(root.left) if found: ans = root found = False if root == p: found = True helper(root.right) helper(root) return ans
Given a binary tree, determine if it is a valid binary search tree (BST). Assume a BST is defined as follows: The left subtree of a node contains only nodes with keys less than the node’s key. The right subtree of a node contains only nodes with keys greater than the node’s key. Both the left and right subtrees must also be binary search trees.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Example 1: Input: 2 / \ 1 3 Output: true
Example 2:
5 / \ 1 4 / \ 3 6 Output: false
Explanation: The input is: [5,1,4,null,null,3,6]. The root node's value is 5 but its right child's value is 4.
高频 递归:
1 2 3 4 5 6 7
classSolution: defisValidBST(self, root: Optional[TreeNode]) -> bool: defdfs(root, l, h): ifnot root: returnTrue return dfs(root.left, l, root.val) and dfs(root.right, root.val, h) and l < root.val < h return dfs(root, -sys.maxsize, sys.maxsize)
inorder 中序遍历无额外数组:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defisValidBST(self, root): stack = [] pre = None while root or stack: if root: stack.append(root) root = root.left else: root = stack.pop(-1) if pre and pre.val >= root.val: returnFalse pre = root root = root.right returnTrue
inorder 中序递归无额外数组:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution: defisValidBST(self, root: TreeNode) -> bool: defin_order(root): nonlocal pre, ans ifnot root: return in_order(root.left) if pre and pre.val >= root.val: ans = False return pre = root in_order(root.right) pre = None ans = True inorder(root) return ans
inorder 中序递归额外数组:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution: defisValidBST(self, root: Optional[TreeNode]) -> bool: defin_order(root): ifnot root: return in_order(root.left) res.append(root.val) in_order(root.right) res = [] in_order(root) for i inrange(1, len(res)): if res[i] <= res[i - 1]: returnFalse returnTrue
8刷:高频,五种解法:1.利用BST性质的递归,2,3.中序遍历递归(有/无额外数组),4,5.中序遍历遍历(有/无额外数组) 中序遍历遍历无额外数组:…if pre and n.val <= pre.val: return False; pre = n…
Given two non-empty binary trees s and t, check whether tree t has exactly the same structure and node values with a subtree of s. A subtree of s is a tree consists of a node in s and all of this node’s descendants. The tree s could also be considered as a subtree of itself.
You need to construct a string consists of parenthesis and integers from a binary tree with the preorder traversing way. The null node needs to be represented by empty parenthesis pair “()”. And you need to omit all the empty parenthesis pairs that don’t affect the one-to-one mapping relationship between the string and the original binary tree.
Example 1: Input: Binary tree: [1,2,3,4] 1 / \ 2 3 / 4 Output: "1(2(4))(3)" Explanation: Originallay it needs to be "1(2(4)())(3()())", but you need to omit all the unnecessary empty parenthesis pairs. And it will be "1(2(4))(3)".
Output: "1(2()(4))(3)" Explanation: Almost the same as the first example, except we can't omit the first parenthesis pair to break the one-to-one mapping relationship between the input and the output.
写法1:
1 2 3 4 5 6 7 8 9 10 11 12
classSolution: deftree2str(self, t: TreeNode) -> str: ifnot t: return'' l = self.tree2str(t.left) r = self.tree2str(t.right) if r: returnf"{t.val}({l})({r})" elif l: returnf"{t.val}({l})" else: returnf"{t.val}"
classSolution: deftree2str(self, t: TreeNode) -> str: defhelper(root): nonlocal ans ifnot root: return ans += str(root.val) if root.right: ans += '(' helper(root.left) ans += ')(' helper(root.right) ans += ')' elif root.left: ans += '(' helper(root.left) ans += ')' ans = '' helper(t) return ans
Serialization is the process of converting a data structure or object into a sequence of bits so that it can be stored in a file or memory buffer, or transmitted across a network connection link to be reconstructed later in the same or another computer environment. Design an algorithm to serialize and deserialize a binary tree. There is no restriction on how your serialization/deserialization algorithm should work. You just need to ensure that a binary tree can be serialized to a string and this string can be deserialized to the original tree structure.
1 2 3 4 5 6 7 8
Example: You may serialize the following tree: 1 / \ 2 3 / \ 4 5 as "[1,2,3,null,null,4,5]"
Clarification: The above format is the same as how LeetCode serializes a binary tree. You do not necessarily need to follow this format, so please be creative and come up with different approaches yourself. Note: Do not use class member/global/static variables to store states. Your serialize and deserialize algorithms should be stateless.
LinC 880. Construct Binary Tree from String (Medium) You need to construct a binary tree from a string consisting of parenthesis and integers. The whole input represents a binary tree. It contains an integer followed by zero, one or two pairs of parenthesis. The integer represents the root’s value and a pair of parenthesis contains a child binary tree with the same structure. You always start to construct the left child node of the parent first if it exists.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
Example 1: Input: "-4(2(3)(1))(6(5))" Output: {-4,2,6,3,1,5} Explanation: The output is look like this: -4 / \ 2 6 / \ / 3 1 5
Example 2: Input: "1(-1)" Output: {1,-1} Explanation: The output is look like this: 1 / -1
Notice There will only be ‘(‘, ‘)’, ‘-‘ and ‘0’ ~ ‘9’ in the input string. An empty tree is represented by “” instead of “()”.
classSolution: defstr2tree(self, s): ifnot s: return stack = [] i = 0 while i < len(s): cur = '' while s[i] and s[i] notin'()': cur += s[i] i += 1 if cur: root = TreeNode(int(cur)) if stack: if stack[-1].left: stack[-1].right = root else: stack[-1].left = root stack.append(root) if s[i] == ")": stack.pop() i += 1 return stack[0]
Return any binary tree that matches the given preorder and postorder traversals. Values in the traversals pre and post are distinct positive integers.
Example 1: Input: pre = [1,2,4,5,3,6,7], post = [4,5,2,6,7,3,1] Output: [1,2,3,4,5,6,7]
Note: 1 <= pre.length == post.length <= 30 pre[] and post[] are both permutations of 1, 2, …, pre.length. It is guaranteed an answer exists. If there exists multiple answers, you can return any of them.
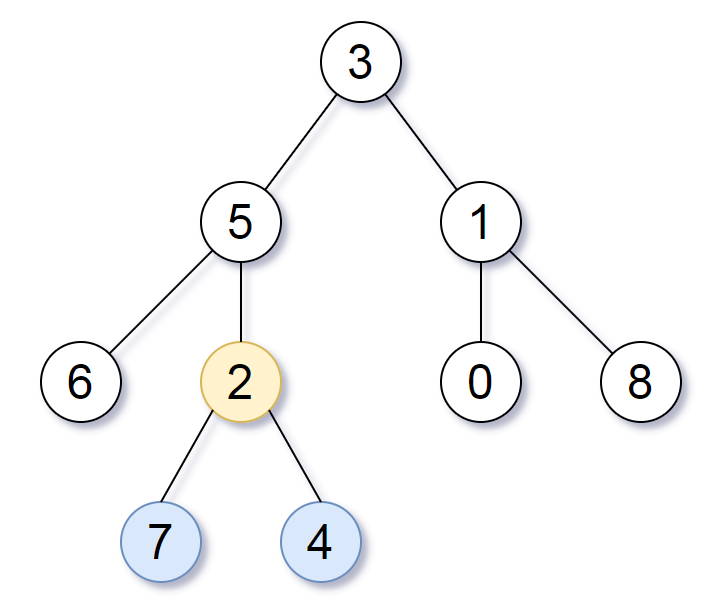
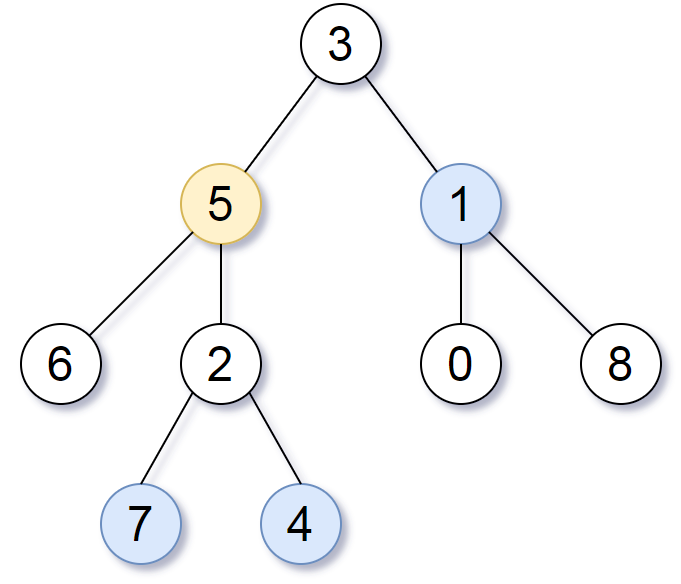
Given a binary tree rooted at root, the depth of each node is the shortest distance to the root. A node is deepest if it has the largest depth possible among any node in the entire tree. The subtree of a node is that node, plus the set of all descendants of that node. Return the node with the largest depth such that it contains all the deepest nodes in its subtree.
Example 1: Input: [3,5,1,6,2,0,8,null,null,7,4] Output: [2,7,4] Explanation: We return the node with value 2, colored in yellow in the diagram. The nodes colored in blue are the deepest nodes of the tree. The input “[3, 5, 1, 6, 2, 0, 8, null, null, 7, 4]” is a serialization of the given tree. The output “[2, 7, 4]” is a serialization of the subtree rooted at the node with value 2. Both the input and output have TreeNode type.
Note: The number of nodes in the tree will be between 1 and 500. The values of each node are unique.
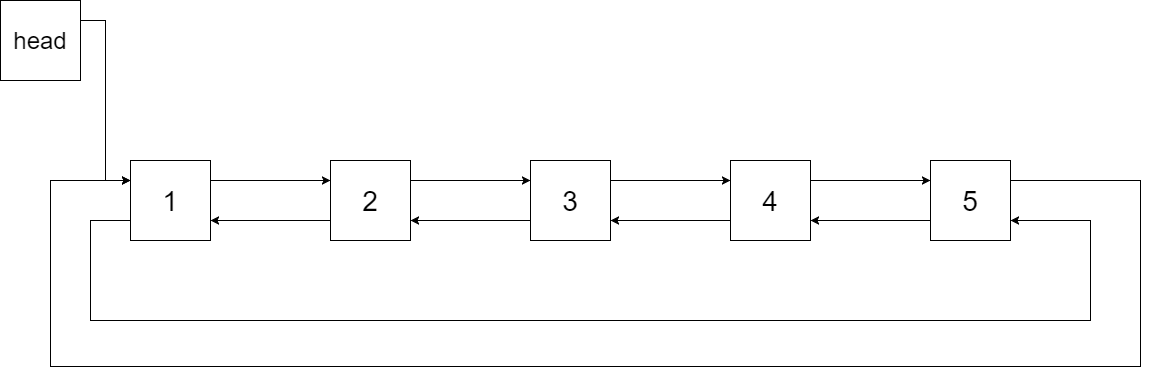
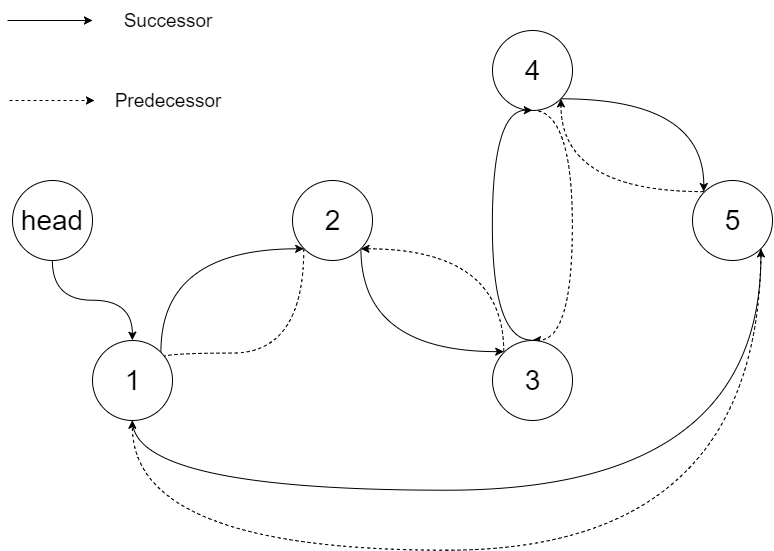
Convert a BST to a sorted circular doubly-linked list in-place. Think of the left and right pointers as synonymous to the previous and next pointers in a doubly-linked list. Let’s take the following BST as an example, it may help you understand the problem better: We want to transform this BST into a circular doubly linked list. Each node in a doubly linked list has a predecessor and successor. For a circular doubly linked list, the predecessor of the first element is the last element, and the successor of the last element is the first element. The figure below shows the circular doubly linked list for the BST above. The “head” symbol means the node it points to is the smallest element of the linked list. Specifically, we want to do the transformation in place. After the transformation, the left pointer of the tree node should point to its predecessor, and the right pointer should point to its successor. We should return the pointer to the first element of the linked list. The figure below shows the transformed BST. The solid line indicates the successor relationship, while the dashed line means the predecessor relationship.
""" Definition of TreeNode: class TreeNode: def __init__(self, val): self.val = val self.left, self.right = None, None """ classSolution: deftreeToDoublyList(self, root): ifnot root: return head = None pre = None defhelper(root): nonlocal head, pre ifnot root: return helper(root.left) ifnot head: head = root if pre: root.left = pre pre.right = root pre = root helper(root.right) helper(root) head.left = pre pre.right = head return head
四刷:Facebook tag。中序遍历可以升序遍历。连接相邻结点,需要用变量 pre 记录上一个遍历到的结点。需要变量head来指向最小(最左)的节点。在递归函数中,先判空,之后对左子结点递归调用,一直递归到最左结点。此时如果 head 为空的话,那么当前就是最左结点,赋值给 head 然后给 pre,对于之后遍历到的结点,就可以和 pre 接上
LinC 595. Binary Tree Longest Consecutive Sequence Given a binary tree, find the length of the longest consecutive sequence path. The path refers to any sequence of nodes from some starting node to any node in the tree along the parent-child connections. The longest consecutive path need to be from parent to child (cannot be the reverse).
Given a binary search tree, rearrange the tree in in-order so that the leftmost node in the tree is now the root of the tree, and every node has no left child and only 1 right child.
Imagine that when you put one of them to cover the other, some nodes of the two trees are overlapped while the others are not. You need to merge the two trees into a new binary tree. The merge rule is that if two nodes overlap, then sum node values up as the new value of the merged node. Otherwise, the NOT null node will be used as the node of the new tree.
Return the merged tree.
Note: The merging process must start from the root nodes of both trees.
classSolution: deflevelOrder(self, root: TreeNode) -> List[List[int]]: ifnot root: return [] ans, cur = [], [root] while cur: res, nCur = [], [] for root in cur: res.append(root.val) if root.left: nCur.append(root.left) if root.right: nCur.append(root.right) ans.append(res) cur = nCur return ans
LinC 71. Binary Tree Zigzag Order Traversal Given a binary tree, return the zigzag level order traversal of its nodes’ values. (ie, from left to right, then right to left for the next level and alternate between).
1 2 3 4 5 6 7 8 9 10 11 12 13
For example: Given binary tree [3,9,20,null,null,15,7], 3 / \ 9 20 / \ 15 7 return its zigzag level order traversal as: [ [3], [20,9], [15,7] ]
DFS:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution: defzigzagLevelOrder(self, root: Optional[TreeNode]) -> List[List[int]]: defdfs(root, d): ifnot root: return iflen(ans) - 1 < d: ans.append(deque()) if d % 2: ans[d].appendleft(root.val) else: ans[d].append(root.val) dfs(root.left, d + 1) dfs(root.right, d + 1) ans = [] dfs(root, 0) return ans
classSolution: defzigzagLevelOrder(self, root): ifnot root: return [] q = [root] ans = [] zig = True while q: ans.append([root.val for root in q]) ifnot zig: ans[-1].reverse() zig = not zig nq = [] for root in q: if root.left: nq.append(root.left) if root.right: nq.append(root.right) q = nq return ans
Given a binary tree, determine if it is a complete binary tree. Definition of a complete binary tree from Wikipedia: In a complete binary tree every level, except possibly the last, is completely filled, and all nodes in the last level are as far left as possible. It can have between 1 and 2h nodes inclusive at the last level h.
Example 1: Input: [1,2,3,4,5,6] Output: true Explanation: Every level before the last is full (ie. levels with node-values {1} and {2, 3}), and all nodes in the last level ({4, 5, 6}) are as far left as possible.
Example 2: Input: [1,2,3,4,5,null,7] Output: false Explanation: The node with value 7 isn’t as far left as possible.
classSolution: """ @param nums: The integer array. @param target: Target to find. @return: The first position of target. Position starts from 0. """ defbinarySearch(self, nums, target): # write your code here if (len(nums) == 0): return -1 start, end = 0, len(nums) - 1 while (start + 1 < end): mid = start + (end - start) // 2 if (nums[mid] >= target): end = mid else: start = mid if (nums[start] == target): return start if (nums[end] == target): return end return -1
You are a product manager and currently leading a team to develop a new product. Unfortunately, the latest version of your product fails the quality check. Since each version is developed based on the previous version, all the versions after a bad version are also bad.
Suppose you have n versions [1, 2, ..., n] and you want to find out the first bad one, which causes all the following ones to be bad.
You are given an API bool isBadVersion(version) which will return whether version is bad. Implement a function to find the first bad version. You should minimize the number of calls to the API.
Example:
Given n = 5, and version = 4 is the first bad version.
# The isBadVersion API is already defined for you. # @param version, an integer # @return an integer # def isBadVersion(version):
classSolution: deffirstBadVersion(self, n): """ :type n: int :rtype: int """ l, r = 0, n while l + 1 < r: mid = l + (r - l) // 2 ifnot isBadVersion(mid): l = mid + 1 else: r = mid return l if isBadVersion(l) else r
LinC 585. Maximum Number in Mountain Sequence (Medium) Given a mountain sequence of n integers which increase firstly and then decrease, find the mountain top. Example Given nums = [1, 2, 4, 8, 6, 3] return 8 Given nums = [10, 9, 8, 7], return 10
思路:切一刀,判断递增就扔左边,递减就扔右边, 不然就找到了中点 二刷:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution: defpeakIndexInMountainArray(self, A): """ :type A: List[int] :rtype: int """ start, end = 0, len(A) - 1 while start + 1 < end: mid = start + (end - start) // 2 if A[mid - 1] < A[mid] < A[mid + 1]: start = mid elif A[mid - 1] > A[mid] > A[mid + 1]: end = mid else: return mid return start if A[start] > A[end] else end
A peak element is an element that is greater than its neighbors. Given an input array nums, where nums[i] ≠ nums[i+1], find a peak element and return its index. The array may contain multiple peaks, in that case return the index to any one of the peaks is fine. You may imagine that nums[-1] = nums[n] = -∞.
Example 1: Input: nums = [1,2,3,1] Output: 2 Explanation: 3 is a peak element and your function should return the index number 2.
Example 2: Input: nums = [1,2,1,3,5,6,4] Output: 1 or 5 Explanation: Your function can return either index number 1 where the peak element is 2, or index number 5 where the peak element is 6. Note: Your solution should be in logarithmic complexity.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution: deffindPeakElement(self, nums: List[int]) -> int: defget(i): if i == -1or i == n: returnfloat('-inf') return nums[i] n = len(nums) l, r = 0, n - 1 while l + 1 < r: mid = l + (r - l) // 2 if nums[mid - 1] < nums[mid] > nums[mid + 1]: return mid elif nums[mid - 1] < nums[mid] < nums[mid + 1]: l = mid + 1 else: r = mid - 1 return r if nums[l] < nums[r] else l
This is a follow up problem to Search in Rotated Sorted Array, where nums may contain duplicates. Would this affect the run-time complexity? How and why?
Given a sorted array and a target value, return the index if the target is found. If not, return the index where it would be if it were inserted in order.
You may assume no duplicates in the array.
Example 1:
Input: [1,3,5,6], 5 Output: 2 Example 2:
Input: [1,3,5,6], 2 Output: 1 Example 3:
Input: [1,3,5,6], 7 Output: 4 Example 4:
Input: [1,3,5,6], 0 Output: 0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution: defsearchInsert(self, nums: List[int], target: int) -> int: l, r = 0, len(nums) - 1 while l + 1 < r: mid = l + (r - l) // 2 if nums[mid] == target: return mid elif nums[mid] < target: l = mid else: r = mid if target <= nums[l]: return l if target <= nums[r]: return r returnlen(nums)
Given a sorted array, two integers k and x, find the k closest elements to x in the array. The result should also be sorted in ascending order. If there is a tie, the smaller elements are always preferred.
Example 1: Input: [1,2,3,4,5], k=4, x=3 Output: [1,2,3,4] Example 2: Input: [1,2,3,4,5], k=4, x=-1 Output: [1,2,3,4] Note: The value k is positive and will always be smaller than the length of the sorted array. Length of the given array is positive and will not exceed 104 Absolute value of elements in the array and x will not exceed 104 UPDATE (2017/9/19): The arr parameter had been changed to an array of integers (instead of a list of integers). Please reload the code definition to get the latest changes.
classSolution: deffindClosestElements(self, arr: List[int], k: int, x: int) -> List[int]: n = len(arr) l, r = 0, n - 1 while l + 1 < r: mid = (l + r) // 2 if arr[mid] < x: l = mid else: r = mid ans = deque() while l >= 0and r < n andlen(ans) < k: ifabs(arr[l] - x) <= abs(arr[r] - x): ans.appendleft(arr[l]) l -= 1 else: ans.append(arr[r]) r += 1 while l >= 0andlen(ans) < k: ans.appendleft(arr[l]) l -= 1 while r < n andlen(ans) < k: ans.append(arr[r]) r += 1 return ans
4刷:二分查找 target,将 l, r 指针放到离x最近的位置…if arr[mid] **<** x: l = **mid** else: r = **mid**…;然后开始往结果里填充k个数 网上还有一种很妖的二分查找一步到位解法,破坏了模板,核心原理是l, r = 0, len(arr) - k…if x - arr[mid] > arr[mid + k] - x: l = mid + 1 else: r = mid; return arr[l: l + k]
You are given an array of positive integers w where w[i] describes the weight of ith index (0-indexed).
We need to call the function pickIndex() which randomly returns an integer in the range [0, w.length - 1]. pickIndex() should return the integer proportional to its weight in the w array. For example, for w = [1, 3], the probability of picking the index 0 is 1 / (1 + 3) = 0.25 (i.e 25%) while the probability of picking the index 1 is 3 / (1 + 3) = 0.75 (i.e 75%).
More formally, the probability of picking index i is w[i] / sum(w).
Example 1: Input ["Solution","pickIndex"] [[[1]],[]] Output [null,0]
Explanation Solution solution = new Solution([1]); solution.pickIndex(); // return 0. Since there is only one single element on the array the only option is to return the first element. Example 2:
Explanation Solution solution = new Solution([1, 3]); solution.pickIndex(); // return 1. It's returning the second element (index = 1) that has probability of 3/4. solution.pickIndex(); // return 1 solution.pickIndex(); // return 1 solution.pickIndex(); // return 1 solution.pickIndex(); // return 0. It's returning the first element (index = 0) that has probability of 1/4.
Since this is a randomization problem, multiple answers are allowed so the following outputs can be considered correct : [null,1,1,1,1,0] [null,1,1,1,1,1] [null,1,1,1,0,0] [null,1,1,1,0,1] [null,1,0,1,0,0] ...... and so on. Constraints: 1 <= w.length <= 10000 1 <= w[i] <= 10^5 pickIndex will be called at most 10000 times.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution:
def__init__(self, w: List[int]): for i inrange(1, len(w)): w[i] += w[i - 1] self.w = w
defpickIndex(self) -> int: target = random.randint(1, self.w[-1]) l, r = 0, len(self.w) - 1 while l + 1 < r: mid = (l + r) // 2 if self.w[mid] < target: l = mid + 1 elif self.w[mid] > target: r = mid else: return mid return l if self.w[l] >= target else r
Design a time-based key-value data structure that can store multiple values for the same key at different time stamps and retrieve the key's value at a certain timestamp.
Implement the TimeMap class:
TimeMap() Initializes the object of the data structure. void set(String key, String value, int timestamp) Stores the key key with the value value at the given time timestamp. String get(String key, int timestamp) Returns a value such that set was called previously, with timestamp_prev <= timestamp. If there are multiple such values, it returns the value associated with the largest timestamp_prev. If there are no values, it returns "".
Explanation TimeMap timeMap = new TimeMap(); timeMap.set("foo", "bar", 1); // store the key "foo" and value "bar" along with timestamp = 1. timeMap.get("foo", 1); // return "bar" timeMap.get("foo", 3); // return "bar", since there is no value corresponding to foo at timestamp 3 and timestamp 2, then the only value is at timestamp 1 is "bar". timeMap.set("foo", "bar2", 4); // store the key "foo" and value "ba2r" along with timestamp = 4. timeMap.get("foo", 4); // return "bar2" timeMap.get("foo", 5); // return "bar2"
Constraints:
1 <= key.length, value.length <= 100 key and value consist of lowercase English letters and digits. 1 <= timestamp <= 107 All the timestamps timestamp of set are strictly increasing. At most 2 * 105 calls will be made to set and get.
Partition an integers array into odd number first and even number second.
Example Given [1, 2, 3, 4], return [1, 3, 2, 4]
思路:双指针一头一尾,碰到不符合的就换。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution: """ @param: nums: an array of integers @return: nothing """ defpartitionArray(self, nums): # write your code here iflen(nums) < 2: return l, r = 0, len(nums) - 1 while l < r: while l < r and nums[l] % 2 != 0: l += 1 while l < r and nums[r] % 2 == 0: r -= 1 if nums[l] % 2 == 0or nums[r] % 2 != 0: nums[l], nums[r] = nums[r], nums[l] if nums[l] % 2 == 0or nums[r] % 2 != 0: nums[l], nums[r] = nums[r], nums[l]
Given a sorted array nums, remove the duplicates in-place such that each element appear only once and return the new length.
Do not allocate extra space for another array, you must do this by modifying the input array in-place with O(1) extra memory.
Example 1:
Given nums = [1,1,2],
Your function should return length = 2, with the first two elements of nums being 1 and 2 respectively.
It doesn't matter what you leave beyond the returned length. Example 2:
Given nums = [0,0,1,1,1,2,2,3,3,4],
Your function should return length = 5, with the first five elements of nums being modified to 0, 1, 2, 3, and 4 respectively.
It doesn't matter what values are set beyond the returned length. Clarification:
Confused why the returned value is an integer but your answer is an array?
Note that the input array is passed in by reference, which means modification to the input array will be known to the caller as well.
Internally you can think of this:
// nums is passed in by reference. (i.e., without making a copy) int len = removeDuplicates(nums);
// any modification to nums in your function would be known by the caller. // using the length returned by your function, it prints the first len elements. for (int i = 0; i < len; i++) { print(nums[i]); }
思路:简单题, 慢指针只有在快指针碰到不同的值才走。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution: defremoveDuplicates(self, nums): """ :type nums: List[int] :rtype: int """ iflen(nums) == 0: return0 slow, fast = 0, 1 while fast < len(nums): if nums[fast] == nums[slow]: fast += 1 else: slow += 1 nums[slow] = nums[fast] fast += 1 return slow + 1
总结:纯热身,秒解
二刷
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: defremoveDuplicates(self, nums: List[int]) -> int: iflen(nums) <= 1: returnlen(nums) slow, fast = 0, 1 while fast < len(nums): if nums[slow] == nums[fast]: fast += 1 else: slow += 1 nums[slow], nums[fast] = nums[fast], nums[slow] fast += 1 return slow + 1
总结:虽然是容易热身题,却要思考两个问题,第一,数组需要 in place sort, 需要利用已经排好序这个条件来在 slow 往前一个以后交换 slow 和 fast 的数; 第二,返回 slow + 1 可以省一个 ans 变量 高频: …else: slow += 1; nums[slow], nums[fast] = nums[fast], nums[slow]; fast += 1…
Given a sorted array nums, remove the duplicates in-place such that duplicates appeared at most twice and return the new length.
Do not allocate extra space for another array, you must do this by modifying the input array in-place with O(1) extra memory.
Example 1:
Given nums = [1,1,1,2,2,3],
Your function should return length = 5, with the first five elements of nums being 1, 1, 2, 2 and 3 respectively.
It doesn't matter what you leave beyond the returned length. Example 2:
Given nums = [0,0,1,1,1,1,2,3,3],
Your function should return length = 7, with the first seven elements of nums being modified to 0, 0, 1, 1, 2, 3 and 3 respectively.
It doesn't matter what values are set beyond the returned length.
1 2 3 4 5 6 7 8 9 10
classSolution: defremoveDuplicates(self, nums: List[int]) -> int: ifnot nums: return0 w = 0 for i, n inenumerate(nums): if i < 2or n != nums[w - 2]: nums[w] = n w += 1 return w
高频:反正两周前的代码也看不懂了,抄个简单一点的…if i < 2 or n != nums[w - 2]
What should we return when needle is an empty string? This is a great question to ask during an interview.
For the purpose of this problem, we will return 0 when needle is an empty string. This is consistent to C's strstr() and Java's indexOf().
思路:快慢指针
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution(object): defstrStr(self, haystack, needle): """ :type haystack: str :type needle: str :rtype: int """ iflen(needle) == 0: return0 iflen(haystack) == 0: return -1 for i inrange(len(haystack)): if haystack[i] == needle[0]: if i + len(needle) - 1 < len(haystack): if needle == haystack[i: i + len(needle)]: return i else: return -1 return -1
总结: 思路是双指针没问题,实际用 python 的时候可以用 python 的性质直接取子串
二刷:
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: defstrStr(self, haystack: str, needle: str) -> int: iflen(needle) == 0: return0 iflen(haystack) == 0: return -1 end = len(haystack) - len(needle) + 1 if end < 0: return -1 for i inrange(0, end): if haystack[i:i + len(needle)] == needle: return i return -1
总结:注意空串的时候要返回 int 而不是 bool, needle 为空时,直接返回 0, 优化 end = len(haystack) - len(needle) + 1; if end < 0: return -1; for i in range(0, end) 高频:考点 end = lh - ln + 1; … if haystack[i:i + ln] == needle: return i。代码能优化一点点,但是大同小异。
Given an array nums, write a function to move all 0’s to the end of it while maintaining the relative order of the non-zero elements.
Example: Input: [0,1,0,3,12] Output: [1,3,12,0,0]
Note: You must do this in-place without making a copy of the array. Minimize the total number of operations.
1 2 3 4 5 6 7 8 9 10
classSolution: defmoveZeroes(self, nums: List[int]) -> None: l, r = 0, 0 n = len(nums) while r < n: while nums[r] < n and nums[r] == 0: r += 1 nums[l], nums[r] = nums[r], nums[l] l += 1 r += 1
Given a non-empty string s, you may delete at most one character. Judge whether you can make it a palindrome.
Example 1: Input: "aba" Output: True Example 2: Input: "abca" Output: True Explanation: You could delete the character 'c'. Note: The string will only contain lowercase characters a-z. The maximum length of the string is 50000.
暴力 TLE:
1 2 3 4 5 6 7
classSolution: defvalidPalindrome(self, s: str) -> bool: for i inrange(len(s)): t = s[:i] + s[i + 1:] if t == t[::-1]: returnTrue returnFalse
双指针:
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: defvalidPalindrome(self, s: str) -> bool: l, r = 0, len(s) - 1 while l < r: if s[l] != s[r]: break l += 1 r -= 1 if l == r: returnTrue s1 = s[:l] + s[l + 1:] s2 = s[:r] + s[r + 1:] return s1 == s1[::-1] or s2 == s2[::-1]
Given an array of integers, return indices of the two numbers such that they add up to a specific target. You may assume that each input would have exactly one solution, and you may not use the same element twice.
classSolution: deftwoSum(self, nums, target): for i inrange(len(nums)): for j inrange(i + 1, len(nums)): if nums[i] + nums[j] == target: return [i, j]
1 2 3 4 5 6 7
classSolution(object): deftwoSum(self, nums, target): remain = {} for i, n inenumerate(nums): if n in remain: return [remain[n], i] remain[target - n] = i
Given an array of integers that is already sorted in ascending order, find two numbers such that they add up to a specific target number.
The function twoSum should return indices of the two numbers such that they add up to the target, where index1 must be less than index2.
Note:
Your returned answers (both index1 and index2) are not zero-based. You may assume that each input would have exactly one solution and you may not use the same element twice. Example:
Input: numbers = [2,7,11,15], target = 9 Output: [1,2] Explanation: The sum of 2 and 7 is 9. Therefore index1 = 1, index2 = 2.
classTwoSum: keys = {} """ @param: number: An integer @return: nothing """ defadd(self, number): # write your code here if number notin self.keys: self.keys[number] = 1 else: self.keys[number] = 2 """ @param: value: An integer @return: Find if there exists any pair of numbers which sum is equal to the value. """ deffind(self, value): # write your code here for key in self.keys: if value - key in self.keys: if value - key == key: if self.keys[key] == 2: returnTrue else: returnTrue returnFalse
Given an array nums of n integers, are there elements a, b, c in nums such that a + b + c = 0? Find all unique triplets in the array which gives the sum of zero. Note: The solution set must not contain duplicate triplets.
1 2 3 4 5 6 7
Example: Given array nums = [-1, 0, 1, 2, -1, -4], A solution set is: [ [-1, 0, 1], [-1, -1, 2] ]
classSolution: defthreeSum(self, nums): ans = [] n = len(nums) if n > 2: nums.sort() for i inrange(n - 2): if i and nums[i] == nums[i - 1]: continue l, r = i + 1, n - 1 while l < r: t = [nums[i], nums[l], nums[r]] st = sum(t) if st == 0: ans.append(t) l += 1 r -= 1 while nums[l] == nums[l - 1] and l < r: l += 1 while nums[r] == nums[r + 1] and l < r: r -= 1 elif st > 0: r -= 1 else: l += 1 return ans
Given an array of integers, how many three numbers can be found in the array, so that we can build an triangle whose three edges length is the three numbers that we find?
Example Given array S = [3,4,6,7], return 3. They are:
[3,4,6] [3,6,7] [4,6,7] Given array S = [4,4,4,4], return 4. They are:
classSolution: """ @param S: A list of integers @return: An integer """ deftriangleCount(self, S): # write your code here S.sort(reverse=True) sum = 0 for index1, longest inenumerate(S): head, tail = index1 + 1, index1 + 2 while tail < len(S) and S[head] + S[tail] > longest: tail += 1 tail -= 1 while head < tail: sum += tail - head head += 1 while head < tail and S[head] + S[tail] <= longest: tail -= 1 returnsum
总结:看清题目,问的是有多少个这样的三角形, 返回数就行。 全排列效率比较低。 更优解是每次定下最长边, 寻找符合条件的另外两个边的数量。 双指针的解法是将 tail 推到最小不能组成三角形的位置, 退一步, 然后从 tail 到 head 的位置的都可以组, 因为他们相加只会比最长边更长。 然后将 head 进一步(缩短),tail 边加长到大于最长边的位置,新 tail 到 head 的位置又都可以组。
Given an array nums of n integers and an integer target, find three integers in nums such that the sum is closest to target. Return the sum of the three integers. You may assume that each input would have exactly one solution.
Example:
Given array nums = [-1, 2, 1, -4], and target = 1.
The sum that is closest to the target is 2. (-1 + 2 + 1 = 2).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution: defthreeSumClosest(self, nums: List[int], target: int) -> int: ans = None nums.sort() for i inrange(len(nums) - 2): l, r = i + 1, len(nums) - 1 while l < r: t = nums[i] + nums[l] + nums[r] if t == target: return t elif t < target: l += 1 else: r -= 1 if ans == Noneorabs(t - target) < abs(ans - target): ans = t return ans
Description Given an array nums of integers and an int k, partition the array (i.e move the elements in “nums”) such that: All elements < k are moved to the left All elements >= k are moved to the right Return the partitioning index, i.e the first index i nums[i] >= k. You should do really partition in array nums instead of just counting the numbers of integers smaller than k. If all elements in nums are smaller than k, then return nums.length
Example If nums = [3,2,2,1] and k=2, a valid answer is 1.
Challenge Can you partition the array in-place and in O(n)?
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution: defpartitionArray(self, nums, k): iflen(nums) == 0: return0 l, r = 0, len(nums) - 1 while l <= r: while l < len(nums) and nums[l] < k: l += 1 while r >= 0and nums[r] >= k: r -= 1 if l > r: break nums[l], nums[r] = nums[r], nums[l] return l
Find the kth largest element in an unsorted array. Note that it is the kth largest element in the sorted order, not the kth distinct element. Example 1: Input: [3,2,1,5,6,4] and k = 2 Output: 5
Example 2: Input: [3,2,3,1,2,4,5,5,6] and k = 4 Output: 4 Note: You may assume k is always valid, 1 ≤ k ≤ array’s length.
Given an array with n objects colored red, white or blue, sort them in-place so that objects of the same color are adjacent, with the colors in the order red, white and blue. Here, we will use the integers 0, 1, and 2 to represent the color red, white, and blue respectively.
Note: You are not suppose to use the library’s sort function for this problem.
A rather straight forward solution is a two-pass algorithm using counting sort. First, iterate the array counting number of 0’s, 1’s, and 2’s, then overwrite array with total number of 0’s, then 1’s and followed by 2’s. Could you come up with a one-pass algorithm using only constant space?
二刷:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution: defsortColors(self, nums: List[int]) -> None: """ Do not return anything, modify nums in-place instead. """ iflen(nums) <= 1: return l, r, i = 0, len(nums) - 1, 0 while i <= r: if nums[i] == 0and i > l: nums[l], nums[i] = nums[i], nums[l] l += 1 elif nums[i] == 2and i < r: nums[i], nums[r] = nums[r], nums[i] r -= 1 else: i += 1
总结:in place 不数元素的话得用 l, r 和 i, 要过的话需要熟记交换的第二条件分别为 i > l 和 i < r, 其他情况 i 均前进 高频:去掉了一刷繁琐的方法。counting sort只需要count 0和1。1 pass:…while i <= r:…and i > l:…and i < r:… 面经:Celo。3个数要保持两个边界l和r,和一个worker i,交换条件要加…i > l…和…i < r,否则会过度交换导致结果有bug
Given an array nums of n integers and an integer target, are there elements a, b, c, and d in nums such that a + b + c + d = target? Find all unique quadruplets in the array which gives the sum of target.
Note:
The solution set must not contain duplicate quadruplets.
Example:
Given array nums = [1, 0, -1, 0, -2, 2], and target = 0.
A solution set is: [ [-1, 0, 0, 1], [-2, -1, 1, 2], [-2, 0, 0, 2] ]
classSolution: deffourSum(self, nums, target): """ :type nums: List[int] :type target: int :rtype: List[List[int]] """ nums.sort() ans = [] for i inrange(0, len(nums) - 3): if i and nums[i] == nums[i - 1]: continue for j inrange(i + 1, len(nums) - 2): if j != i + 1and nums[j] == nums[j - 1]: continue l, r = j + 1, len(nums) - 1 while l < r: sum = nums[i] + nums[j] + nums[l] + nums[r] ifsum == target: ans.append([nums[i], nums[j], nums[l], nums[r]]) l += 1 r -= 1 while l < r and nums[l] == nums[l - 1]: l += 1 while l < r and nums[r] == nums[r + 1]: r -= 1 elifsum < target: l += 1 else: r -= 1 return ans
总结:有一个自己肯定想不出的条件就是第二层循环怎么跳过:if j != i + 1 and nums[j] == nums[j - 1]: continue; 非常勉强能过 AC. 看了网上和三年前的,都是用 dict 先存 2sum,然后再 loop 两遍,用 if pair[0] > j 来去重(第三个元素的 index 要大于前面两个)。
classSolution: deffourSum(self, nums: List[int], target: int) -> List[List[int]]: ans = [] defnsum(l, r, N, target, path): if r - l + 1 < N or N < 2or N > len(nums) or N * nums[l] > target or N * nums[r] < target: return if N == 2: while l < r: t = nums[l] + nums[r] if t == target: ans.append(path + [nums[l], nums[r]]) while l < r and nums[l] == nums[l + 1]: l += 1 while l < r and nums[r] == nums[r - 1]: r -= 1 l += 1 r -= 1 elif t < target: l += 1 else: r -= 1 else: for i inrange(l, r + 1): if i == l or (i > l and nums[i] != nums[i - 1]): nsum(i + 1, r, N - 1, target - nums[i], path + [nums[i]]) nums.sort() nsum(0, len(nums) - 1, 4, target, []) return ans
二刷:看 leetcode ac 的流行答案, 返回递归 nsum, 递归内终结条件为解决 2sum,,注意两处去重,1.找到 target 以后,在 l < r 条件下跳过所有后面与 l 相同的;2.进入 nsum 前,if i == 0 or (i > 0 and nums[i - 1] != nums[i]) 总结:很多坑,N == 2 时要注意 while l < r 做二分法;N > 2 时 for i in range(l, r + 1); nsum(i + 1, …); 如是高频题需要练熟 高频:…def nsum(l, r, N, target, path): if r - l + 1 < N or N < 2 or…if N == 2: while l < r:… while l < r and nums[l] == nums[l + 1]:…while…l += 1; r -= 1… for i in range(l, r + 1): if (i == l) or…: nsum(i + 1, r…)…
Given an array nums and a value val, remove all instances of that value in-place and return the new length.
Do not allocate extra space for another array, you must do this by modifying the input array in-place with O(1) extra memory.
The order of elements can be changed. It doesn't matter what you leave beyond the new length.
Example 1:
Given nums = [3,2,2,3], val = 3,
Your function should return length = 2, with the first two elements of nums being 2.
It doesn't matter what you leave beyond the returned length. Example 2:
Given nums = [0,1,2,2,3,0,4,2], val = 2,
Your function should return length = 5, with the first five elements of nums containing 0, 1, 3, 0, and 4.
Note that the order of those five elements can be arbitrary.
It doesn't matter what values are set beyond the returned length.
高频
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution: defremoveElement(self, nums: List[int], val: int) -> int: ans = len(nums) i = 0 j = ans - 1 while i <= j: while i <= j and nums[i] != val: i += 1 while i <= j and nums[j] == val: j -= 1 ans -= 1 if i < j: nums[i], nums[j] = nums[j], nums[i] return ans
总结:背while i <= j: while i <= j and … while i <= j and …if i < j: …
Given n non-negative integers a1, a2, …, an , where each represents a point at coordinate (i, ai). n vertical lines are drawn such that the two endpoints of line i is at (i, ai) and (i, 0). Find two lines, which together with x-axis forms a container, such that the container contains the most water.
Note: You may not slant the container and n is at least 2. The above vertical lines are represented by array [1,8,6,2,5,4,8,3,7]. In this case, the max area of water (blue section) the container can contain is 49.
Example: Input: [1,8,6,2,5,4,8,3,7] Output: 49
1 2 3 4 5 6 7 8 9 10
classSolution: defmaxArea(self, height: List[int]) -> int: ans, l, r = 0, 0, len(height) - 1 while l < r: ans = max(ans, (r - l) * min(height[l], height[r])) if height[l] < height[r]: l += 1 else: r -= 1 return ans
Write a function that takes a string as input and reverse only the vowels of a string.
Example 1: Input: “hello” Output: “holle”
Example 2: Input: “leetcode” Output: “leotcede” Note:
1 2 3 4 5 6 7 8 9 10
classSolution: defreverseVowels(self, s: str) -> str: stack = [] for c in s: if c in"aeiouAEIOU": stack.append(c) for i, c inenumerate(s): if c in"aeiouAEIOU": s = s[:i] + stack.pop() + s[i + 1:] return s
inplace:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution: defreverseVowels(self, s: str) -> str: l, r = 0, len(s) - 1 arr = list(s) while l < r: while arr[l] notin"aeiouAEIOU"and l < len(s) - 1: l += 1 while arr[r] notin"aeiouAEIOU"and r > 0: r -= 1 if l < r: arr[l], arr[r] = arr[r], arr[l] l += 1 r -= 1 return"".join(arr)
Given a non-empty 2D array grid of 0's and 1's, an island is a group of 1's (representing land) connected 4-directionally (horizontal or vertical.) You may assume all four edges of the grid are surrounded by water.
Find the maximum area of an island in the given 2D array. (If there is no island, the maximum area is 0.)
Example 1: [[0,0,1,0,0,0,0,1,0,0,0,0,0], [0,0,0,0,0,0,0,1,1,1,0,0,0], [0,1,1,0,1,0,0,0,0,0,0,0,0], [0,1,0,0,1,1,0,0,1,0,1,0,0], [0,1,0,0,1,1,0,0,1,1,1,0,0], [0,0,0,0,0,0,0,0,0,0,1,0,0], [0,0,0,0,0,0,0,1,1,1,0,0,0], [0,0,0,0,0,0,0,1,1,0,0,0,0]] Given the above grid, return 6. Note the answer is not 11, because the island must be connected 4-directionally. Example 2: [[0,0,0,0,0,0,0,0]] Given the above grid, return 0. Note: The length of each dimension in the given grid does not exceed 50.
classSolution: defmaxAreaOfIsland(self, grid: List[List[int]]) -> int: ans = 0 m, n = len(grid), len(grid[0]) for r inrange(m): for c inrange(n): if grid[r][c] == 1: res = 0 q = deque() q.append((r, c)) grid[r][c] = 0 while q: (rq, cq) = q.popleft() res += 1 for dr, dc in [(-1, 0), (1, 0), (0, -1), (0, 1)]: nr, nc = rq + dr, cq + dc if0 <= nr < m and0 <= nc < n and grid[nr][nc] == 1: grid[nr][nc] = 0 q.append((nr, nc)) ans = max(ans, res) return ans
classSolution: defmaxAreaOfIsland(self, grid: List[List[int]]) -> int: defdfs(r, c): nonlocal res res += 1 for dr, dc in [(-1, 0), (1, 0), (0, -1), (0, 1)]: nr, nc = r + dr, c + dc if0 <= nr < m and0 <= nc < n and grid[nr][nc] == 1: grid[nr][nc] = 0 dfs(nr, nc) m, n = len(grid), len(grid[0]) ans = 0 for i inrange(m): for j inrange(n): if grid[i][j] == 1: res = 0 grid[i][j] = 0 dfs(i, j) ans = max(ans, res) return ans
Given a reference of a node in a connected undirected graph. Each node in the graph contains a value (int) and a list (List[Node]) of its neighbors.
class Node { public int val; public List neighbors; }
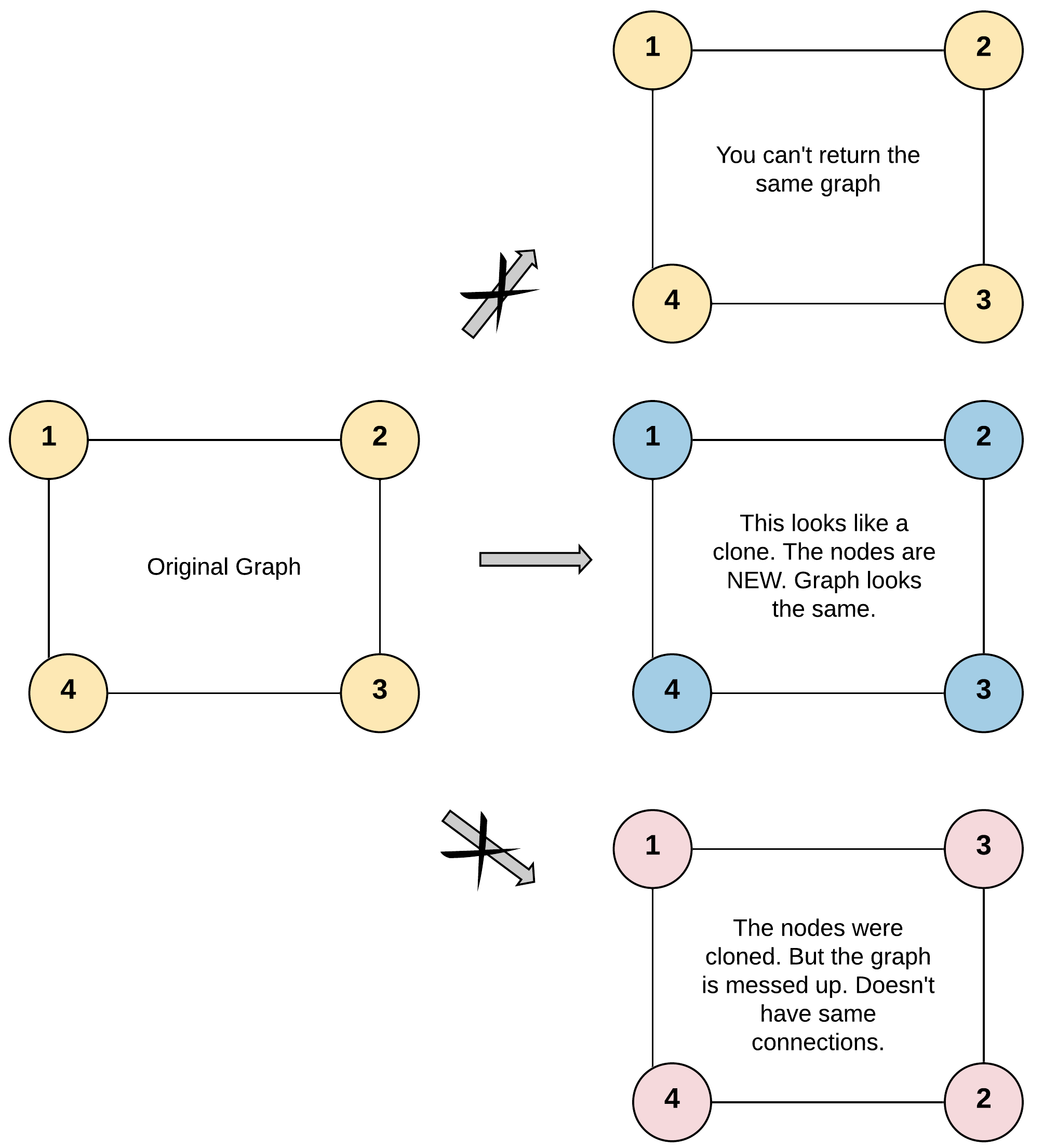
Test case format: For simplicity, each node’s value is the same as the node’s index (1-indexed). For example, the first node with val == 1, the second node with val == 2, and so on. The graph is represented in the test case using an adjacency list. An adjacency list is a collection of unordered lists used to represent a finite graph. Each list describes the set of neighbors of a node in the graph. The given node will always be the first node with val = 1. You must return the copy of the given node as a reference to the cloned graph.
Example 1: Input: adjList = [[2,4],[1,3],[2,4],[1,3]] Output: [[2,4],[1,3],[2,4],[1,3]] Explanation: There are 4 nodes in the graph. 1st node (val = 1)’s neighbors are 2nd node (val = 2) and 4th node (val = 4). 2nd node (val = 2)’s neighbors are 1st node (val = 1) and 3rd node (val = 3). 3rd node (val = 3)’s neighbors are 2nd node (val = 2) and 4th node (val = 4). 4th node (val = 4)’s neighbors are 1st node (val = 1) and 3rd node (val = 3).
Constraints The number of nodes in the graph is in the range [0, 100]. 1 <= Node.val <= 100 Node.val is unique for each node. There are no repeated edges and no self-loops in the graph. The Graph is connected and all nodes can be visited starting from the given node.
""" # Definition for a Node. class Node: def __init__(self, val = 0, neighbors = None): self.val = val self.neighbors = neighbors if neighbors is not None else [] """ classSolution: defcloneGraph(self, node: 'Node') -> 'Node': ifnot node: return d = {} q = deque([node]) while q: old = q.popleft() if old notin d: new_node = Node(old.val) d[old] = new_node for neighbor in old.neighbors: if neighbor notin d: q.append(neighbor) new_neighbor = Node(neighbor.val) d[neighbor] = new_neighbor d[old].neighbors.append(d[neighbor]) return d[node]
dfs:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defcloneGraph(self, node: 'Node') -> 'Node': defdfs(n): if n in d: return nn = Node(n.val) d[n] = nn for neighbor in n.neighbors: dfs(neighbor) nn.neighbors.append(d[neighbor]) ifnot node: return d = {} dfs(node) return d[node]
Given two words (beginWord and endWord), and a dictionary’s word list, find the length of shortest transformation sequence from beginWord to endWord, such that: Only one letter can be changed at a time. Each transformed word must exist in the word list. Note that beginWord is not a transformed word. Note: Return 0 if there is no such transformation sequence. All words have the same length. All words contain only lowercase alphabetic characters. You may assume no duplicates in the word list. You may assume beginWord and endWord are non-empty and are not the same.
Example 1: Input: beginWord = “hit”, endWord = “cog”, wordList = [“hot”,”dot”,”dog”,”lot”,”log”,”cog”] Output: 5 Explanation: As one shortest transformation is “hit” -> “hot” -> “dot” -> “dog” -> “cog”, return its length 5.
Example 2: Input: beginWord = “hit” endWord = “cog” wordList = [“hot”,”dot”,”dog”,”lot”,”log”] Output: 0 Explanation: The endWord “cog” is not in wordList, therefore no possible transformation.
可以输出此path:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution: defladderLength(self, beginWord: str, endWord: str, wordList: List[str]) -> int: if endWord notin wordList orlen(beginWord) != len(endWord): return0 q = [[beginWord]] wordList = set(wordList) visited = set() while q: curPath = q.pop(0) curWord = curPath[-1] if curWord == endWord: returnlen(curPath) for i inrange(len(curWord)): for c in [chr(x) for x inrange(ord("a"), ord("z") + 1)]: newW = curWord[:i] + c + curWord[i + 1:] if newW in wordList and newW notin visited: visited.add(newW) q.append(curPath + [newW]) return0
精简无需输出path:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution: defladderLength(self, beginWord: str, endWord: str, wordList: List[str]) -> int: if endWord notin wordList orlen(beginWord) != len(endWord): return0 q = [(beginWord, 1)] wordList = set(wordList) visited = set() while q: word, length = q.pop(0) if word == endWord: return length for i inrange(len(word)): for c in [chr(i) for i inrange(ord("a"), ord("z"))]: newW = word[:i] + c + word[i + 1:] if newW in wordList and newW notin visited: visited.add(newW) q.append((newW, length + 1)) return0
Given a 2d grid map of '1's (land) and '0's (water), count the number of islands. An island is surrounded by water and is formed by connecting adjacent lands horizontally or vertically. You may assume all four edges of the grid are all surrounded by water.
Example 1: Input: 11110 11010 11000 00000 Output: 1
Example 2: Input: 11000 11000 00100 00011 Output: 3
classSolution: defnumIslands(self, grid: List[List[str]]) -> int: ans = 0 for r inrange(len(grid)): for c inrange(len(grid[0])): if grid[r][c] == "1": ans += 1 grid[r][c] = "0" self.bfs(grid, r, c) return ans defbfs(self, matrix, r, c): q = [(r, c)] while q: r, c = q.pop(0) for dr, dc in [(1, 0), (-1, 0), (0, 1), (0, -1)]: newR = r + dr newC = c + dc if0 <= newR <= len(matrix) - 1and0 <= newC <= len(matrix[0]) - 1and matrix[newR][newC] == "1": matrix[newR][newC] = "0" q.append((newR, newC))
面经,三刷:Amazon。对于 leetcode ac 比较重要的细节是,gird[][] = ‘0’ 这句话要在 if 里面,否则逻辑 OK 但是会 TLE
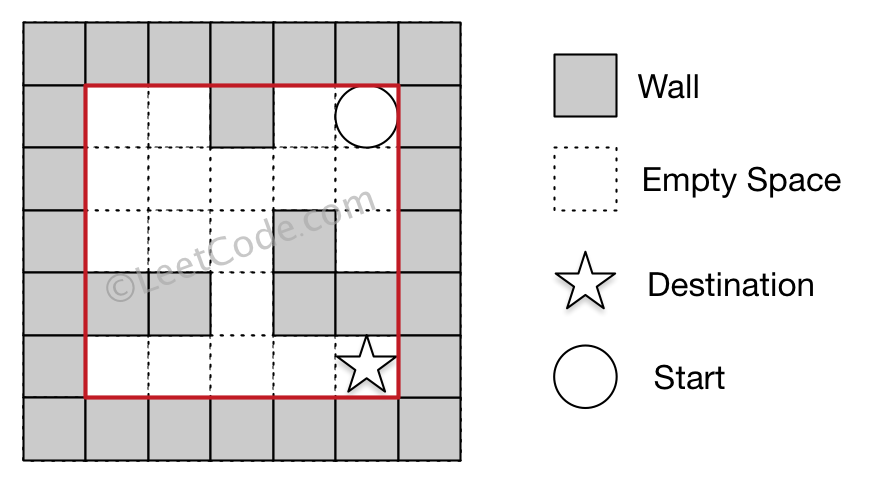
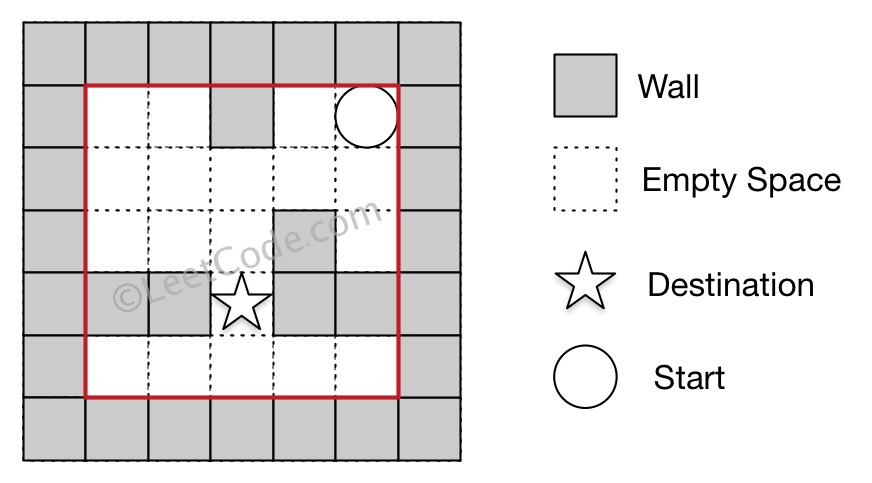
Given a knight in a chessboard (a binary matrix with 0 as empty and 1 as barrier) with a source position, find the shortest path to a destination position, return the length of the route. Return -1 if knight can not reached.
source and destination must be empty. Knight can not enter the barrier.
Clarification If the knight is at (x, y), he can get to the following positions in one step:
(x + 1, y + 2) (x + 1, y - 2) (x - 1, y + 2) (x - 1, y - 2) (x + 2, y + 1) (x + 2, y - 1) (x - 2, y + 1) (x - 2, y - 1) Example [[0,0,0], [0,0,0], [0,0,0]] source = [2, 0] destination = [2, 2] return 2
Given an undirected graph, return true if and only if it is bipartite.
Recall that a graph is bipartite if we can split it's set of nodes into two independent subsets A and B such that every edge in the graph has one node in A and another node in B.
The graph is given in the following form: graph[i] is a list of indexes j for which the edge between nodes i and j exists. Each node is an integer between 0 and graph.length - 1. There are no self edges or parallel edges: graph[i] does not contain i, and it doesn't contain any element twice.
Example 1: Input: [[1,3], [0,2], [1,3], [0,2]] Output: true Explanation: The graph looks like this: 0----1 | | | | 3----2 We can divide the vertices into two groups: {0, 2} and {1, 3}. Example 2: Input: [[1,2,3], [0,2], [0,1,3], [0,2]] Output: false Explanation: The graph looks like this: 0----1 | \ | | \ | 3----2 We cannot find a way to divide the set of nodes into two independent subsets.
Note:
graph will have length in range [1, 100]. graph[i] will contain integers in range [0, graph.length - 1]. graph[i] will not contain i or duplicate values. The graph is undirected: if any element j is in graph[i], then i will be in graph[j].
DFS:
1 2 3 4 5 6 7 8 9
classSolution: defisBipartite(self, graph: List[List[int]]) -> bool: defdfs(n, color): if n in d: return color == d[n] d[n] = color returnall(dfs(v, -color) for v in graph[n]) d = {} returnall(dfs(i, 1) for i inrange(len(graph)) if i notin d)
BFS:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution: defisBipartite(self, graph: List[List[int]]) -> bool: d = {} for i inrange(len(graph)): if i notin d: d[i] = 1 s = [(i, 1)] while s: n, color = s.pop() for v in graph[n]: if v in d: if color == d[v]: returnFalse else: d[v] = -color s.append((v, -color)) returnTrue
Given n nodes labeled from 0 to n - 1 and a list of undirected edges (each edge is a pair of nodes), write a function to check whether these edges make up a valid tree.
You can assume that no duplicate edges will appear in edges. Since all edges are undirected, [0, 1] is the same as [1, 0] and thus will not appear together in edges.
Example Given n = 5 and edges = [[0, 1], [0, 2], [0, 3], [1, 4]], return true.
Given n = 5 and edges = [[0, 1], [1, 2], [2, 3], [1, 3], [1, 4]], return false.
Given a 2D board containing 'X' and 'O' (the letter O), capture all regions surrounded by 'X'.
A region is captured by flipping all 'O's into 'X's in that surrounded region.
Example:
X X X X X O O X X X O X X O X X After running your function, the board should be:
X X X X X X X X X X X X X O X X Explanation:
Surrounded regions shouldn’t be on the border, which means that any 'O' on the border of the board are not flipped to 'X'. Any 'O' that is not on the border and it is not connected to an 'O' on the border will be flipped to 'X'. Two cells are connected if they are adjacent cells connected horizontally or vertically.
You are asked to cut off trees in a forest for a golf event. The forest is represented as a non-negative 2D map, in this map: 0 represents the obstacle can’t be reached. 1 represents the ground can be walked through. The place with number bigger than 1 represents a tree can be walked through, and this positive number represents the tree’s height.
You are asked to cut off all the trees in this forest in the order of tree’s height - always cut off the tree with lowest height first. And after cutting, the original place has the tree will become a grass (value 1). You will start from the point (0, 0) and you should output the minimum steps you need to walk to cut off all the trees. If you can’t cut off all the trees, output -1 in that situation. You are guaranteed that no two trees have the same height and there is at least one tree needs to be cut off.
Example 1: Input: [ [1,2,3], [0,0,4], [7,6,5] ] Output: 6
Example 2: Input: [ [1,2,3], [0,0,0], [7,6,5] ] Output: -1
Example 3: Input: [ [2,3,4], [0,0,5], [8,7,6] ] Output: 6 Explanation: You started from the point (0,0) and you can cut off the tree in (0,0) directly without walking.
classSolution: defcutOffTree(self, forest): m, n = len(forest), len(forest[0]) trees = [[forest[r][c], r, c] for r inrange(m) for c inrange(n) if forest[r][c] > 1] trees.sort(key = lambda x: x[0]) ans = 0 nextR, nextC = 0, 0 for h, r, c in trees: step = self.bfs(forest, nextR, nextC, r, c, m, n) if step == -1: return -1 else: forest[r][c] = 1 nextR, nextC = r, c ans += step return ans defbfs(self, forest, startR, startC, endR, endC, m, n): step = 0 q = [(startR, startC)] dirs = [(-1, 0), (1, 0), (0, -1), (0, 1)] visited = set() while q: nq = [] for _ inrange(len(q)): r, c = q.pop() if r == endR and c == endC: return step visited.add((r, c)) for dr, dc in dirs: if0 <= r + dr <= m - 1and0 <= c + dc <= n - 1and forest[r + dr][c + dc] != 0and (r + dr, c + dc) notin visited: nq.append((r + dr, c + dc)) step += 1 q = nq return -1
For an undirected graph with tree characteristics, we can choose any node as the root. The result graph is then a rooted tree. Among all possible rooted trees, those with minimum height are called minimum height trees (MHTs). Given such a graph, write a function to find all the MHTs and return a list of their root labels. Format The graph contains n nodes which are labeled from 0 to n - 1. You will be given the number n and a list of undirected edges (each edge is a pair of labels). You can assume that no duplicate edges will appear in edges. Since all edges are undirected, [0, 1] is the same as [1, 0] and thus will not appear together in edges.
Note: According to the definition of tree on Wikipedia: “a tree is an undirected graph in which any two vertices are connected by exactly one path. In other words, any connected graph without simple cycles is a tree.” The height of a rooted tree is the number of edges on the longest downward path between the root and a leaf.
classSolution: deffindMinHeightTrees(self, n: int, edges: List[List[int]]) -> List[int]: ifnot edges: return [0] from collections import defaultdict adj = defaultdict(list) for u, v in edges: adj[u].append(v) adj[v].append(u) leaves = [k for k, v in adj.items() iflen(v) == 1] while n > 2: n -= len(leaves) newLeaves = [] for u in leaves: v = adj[u].pop() adj[v].remove(u) iflen(adj[v]) == 1: newLeaves.append(v) leaves = newLeaves return leaves
Given an directed graph, a topological order of the graph nodes is defined as follow:
For each directed edge A -> B in graph, A must before B in the order list. The first node in the order can be any node in the graph with no nodes direct to it. Find any topological order for the given graph. You can assume that there is at least one topological order in the graph. Clarification Learn more about representation of graphs
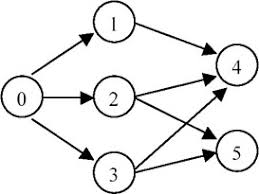
Example: For graph as follow: The topological order can be: [0, 1, 2, 3, 4, 5] [0, 2, 3, 1, 5, 4] 思路:拓扑排序,算法貌似是:1.统计每个点的入度;2.将入度为 0 的点入 queue;3.从队列中 pop 点,去掉所有指向别的点的边: 相应点入度 -1;4.新入度为 0 的点入 queue
""" Definition for a Directed graph node class DirectedGraphNode: def __init__(self, x): self.label = x self.neighbors = [] """ classSolution: """ @param: graph: A list of Directed graph node @return: Any topological order for the given graph. """ deftopSort(self, graph): # write your code here iflen(graph) == 0: return [] ans = [] inBound = {} for node in graph: if node notin inBound: inBound[node] = 0 for neighbor in node.neighbors: if neighbor notin inBound: inBound[neighbor] = 0 inBound[neighbor] += 1 q = collections.deque() for node in inBound: if inBound[node] == 0: q.append(node) while q: zNode = q.popleft() ans.append(zNode) for node in zNode.neighbors: inBound[node] -= 1 if inBound[node] == 0: q.append(node) return ans
There are a total of n courses you have to take, labeled from 0 to n-1. Some courses may have prerequisites, for example to take course 0 you have to first take course 1, which is expressed as a pair: [0,1] Given the total number of courses and a list of prerequisite pairs, is it possible for you to finish all courses?
Example 1: Input: 2, [[1,0]] Output: true Explanation: There are a total of 2 courses to take. To take course 1 you should have finished course 0. So it is possible.
Example 2: Input: 2, [[1,0],[0,1]] Output: false Explanation: There are a total of 2 courses to take. To take course 1 you should have finished course 0, and to take course 0 you should also have finished course 1. So it is impossible.
Note: The input prerequisites is a graph represented by a list of edges, not adjacency matrices. Read more about how a graph is represented. You may assume that there are no duplicate edges in the input prerequisites.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution: defcanFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool: inDegree = [0] * numCourses graph = defaultdict(list) for [c, pre] in prerequisites: inDegree[c] += 1 graph[pre].append(c) q = deque([i for i, v inenumerate(inDegree) if v == 0]) while q: for pre in graph[q.popleft()]: inDegree[pre] -= 1 if inDegree[pre] == 0: q.append(pre) returnsum(inDegree) == 0
There are a total of n courses you have to take, labeled from 0 to n-1. Some courses may have prerequisites, for example to take course 0 you have to first take course 1, which is expressed as a pair: [0,1] Given the total number of courses and a list of prerequisite pairs, return the ordering of courses you should take to finish all courses. There may be multiple correct orders, you just need to return one of them. If it is impossible to finish all courses, return an empty array.
Example 1: Input: 2, [[1,0]] Output: [0,1] Explanation: There are a total of 2 courses to take. To take course 1 you should have finished course 0. So the correct course order is [0,1] .
Example 2: Input: 4, [[1,0],[2,0],[3,1],[3,2]] Output: [0,1,2,3] or [0,2,1,3] Explanation: There are a total of 4 courses to take. To take course 3 you should have finished both courses 1 and 2. Both courses 1 and 2 should be taken after you finished course 0. So one correct course order is [0,1,2,3]. Another correct ordering is [0,2,1,3] . Note: The input prerequisites is a graph represented by a list of edges, not adjacency matrices. Read more about how a graph is represented. You may assume that there are no duplicate edges in the input prerequisites.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution: deffindOrder(self, numCourses: int, prerequisites: List[List[int]]) -> List[int]: p2c = collections.defaultdict(list) inD = [0] * numCourses for [c, p] in prerequisites: p2c[p].append(c) inD[c] += 1 q = [i for i inrange(numCourses) if inD[i] == 0] ans = q[:] while q: p = q.pop() for c in p2c[p]: inD[c] -= 1 if inD[c] == 0: ans.append(c) q.append(c) return ans iflen(ans) == numCourses else []
2刷:面经:Cruise。时间复杂度:O(v + e) number of vertices and edges, 空间复杂度: O(v + e)
classSolution: defsubsets(self, nums): defdfs(idx): ans.append(cur[:]) for i inrange(idx, len(nums)): cur.append(nums[i]) dfs(i + 1) del cur[-1] cur, ans = [], [] dfs(0) return ans
Given a set of candidate numbers (candidates) (without duplicates) and a target number (target), find all unique combinations in candidates where the candidate numbers sums to target. The same repeated number may be chosen from candidates unlimited number of times. Note: All numbers (including target) will be positive integers. The solution set must not contain duplicate combinations.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Example 1: Input: candidates = [2,3,6,7], target = 7, A solution set is: [ [7], [2,2,3] ]
Example 2: Input: candidates = [2,3,5], target = 8, A solution set is: [ [2,2,2,2], [2,3,3], [3,5] ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution: defcombinationSum(self, candidates, target): nums = sorted(candidates) defdfs(idx): ifsum(cur) == target: ans.append(cur[:]) return for i inrange(idx, len(nums)): if nums[i] + sum(cur) <= target: cur.append(nums[i]) dfs(i) del cur[-1] ans = [] cur = [] dfs(0) return ans
Given a collection of candidate numbers (candidates) and a target number (target), find all unique combinations in candidates where the candidate numbers sums to target. Each number in candidates may only be used once in the combination. Note: All numbers (including target) will be positive integers. The solution set must not contain duplicate combinations.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
Example 1: Input: candidates = [10,1,2,7,6,1,5], target = 8, A solution set is: [ [1, 7], [1, 2, 5], [2, 6], [1, 1, 6] ]
Example 2: Input: candidates = [2,5,2,1,2], target = 5, A solution set is: [ [1,2,2], [5] ]
find all possible combinations of k numbers that add up to a number n, given that only numbers from 1 to 9 can be used and each combination should be a unique set of numbers. note: all numbers will be positive integers. the solution set must not contain duplicate combinations.
1 2 3 4 5 6 7
example 1: input: k = 3, n = 7 output: [[1,2,4]]
example 2: input: k = 3, n = 9 output: [[1,2,6], [1,3,5], [2,3,4]]
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classsolution: defcombinationsum3(self, k, n): defdfs(i): iflen(cur) == k andsum(cur) == n: ans.append(cur[:]) return for j inrange(i, 10): iflen(cur) < k andsum(cur) < n: cur.append(j) dfs(j + 1) del cur[-1] ans, cur = [], [] dfs(1) return ans
given two integers n and k, return all possible combinations of k numbers out of 1 … n.
example: input: n = 4, k = 2 output: [ [2,4], [3,4], [2,3], [1,2], [1,3], [1,4], ]
1 2 3 4 5 6 7 8 9 10 11 12 13
classsolution: defcombine(self, n: int, k: int) -> list[list[int]]: defdfs(idx): iflen(cur) == k: ans.append(cur[:]) return for i inrange(idx, n + 1): cur.append(i) dfs(i + 1) del cur[-1] ans, cur = [], [] dfs(1) return ans
classsolution: defpartition(self, s: str) -> list[list[str]]: ans = [] cur = [] defdfs(idx): if idx == len(s): ans.append(cur[:]) return for i inrange(idx + 1, len(s) + 1): w = s[idx : i] if w == w[::-1]: cur.append(w) dfs(i) del cur[-1] ans, cur = [], [] dfs(0) return ans
give a string, you can choose to split the string after one character or two adjacent characters, and make the string to be composed of only one character or two characters. output all possible results.
example given the string "123" return [["1","2","3"],["12","3"],["1","23"]]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classsolution: defsplitstring(self, s): iflen(s) == 0: return [[]] defdfs(idx): if idx == len(s): ans.append(cur[:]) return for i inrange(1, 3): if idx + i <= len(s): cur.append(s[idx:idx + i]) dfs(idx + i) del cur[-1] ans, cur = [], [] dfs(0) return ans
classsolution: defsubsetswithdup(self, nums: list[int]) -> list[list[int]]: defdfs(idx): ans.append(cur[:]) for i inrange(idx, len(nums)): if i > idx and nums[i] == nums[i - 1]: continue cur.append(nums[i]) dfs(i + 1) del cur[-1] nums.sort() ans, cur = [], [] dfs(0) return ans
有额外空间:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classsolution: defsubsetswithdup(self, nums: list[int]) -> list[list[int]]: defdfs(idx): ans.append(cur[:]) for i inrange(idx, len(nums)): if i > 0and nums[i] == nums[i - 1] andnot used[i - 1]: continue cur.append(nums[i]) used[i] = true dfs(i + 1) used[i] = false del cur[-1] nums.sort() ans, cur = [], [] used = [false for _ inrange(len(nums))] dfs(0) return ans
8刷:高频,无额外空间的解法需要if i > idx and …是因为要防止第一次就跳过重复的数字。在47题:permutations ii中因为全排列没有idx这个参数,需要用到用额外空间的写法去重
Given a non-empty string s and a dictionary wordDict containing a list of non-empty words, add spaces in s to construct a sentence where each word is a valid dictionary word. Return all such possible sentences.
Note:
The same word in the dictionary may be reused multiple times in the segmentation. You may assume the dictionary does not contain duplicate words. Example 1:
Input: s = “catsanddog” wordDict = [“cat”, “cats”, “and”, “sand”, “dog”] Output: [ “cats and dog”, “cat sand dog” ] Example 2:
Input: s = “pineapplepenapple” wordDict = [“apple”, “pen”, “applepen”, “pine”, “pineapple”] Output: [ “pine apple pen apple”, “pineapple pen apple”, “pine applepen apple” ] Explanation: Note that you are allowed to reuse a dictionary word. Example 3:
classSolution: defwordBreak(self, s: str, wordDict: List[str]) -> List[str]: defdfs(idx): if idx == n: ans.append(' '.join(cur)) return for i inrange(idx + 1, n + 1): w = s[idx: i] if w in wordDict: cur.append(w) dfs(i) del cur[-1] n = len(s) ans, cur = [], [] dfs(0) return ans
AC: dfs + memo 写法1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution: defwordBreak(self, s: str, wordDict: List[str]) -> List[str]: defdfs(idx): if idx in memo: return memo[idx] res = [] for w in wordDict: if s[idx:].startswith(w): if w == s[idx:]: res.append(w) else: restW = dfs(idx + len(w)) for item in restW: res.append(w + ' ' + item) memo[idx] = res return res memo = {} return dfs(0)
写法2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution: defwordBreak(self, s: str, wordDict: List[str]) -> List[str]: defdfs(s): if s in memo: return memo[s] res = [] for w in wordDict: if s.startswith(w): if w == s: res.append(w) else: restW = dfs(s[len(w):]) for item in restW: res.append(w + ' ' + item) memo[s] = res return res memo = {} return dfs(s)
Given an integer array nums and an integer k, return true if it is possible to divide this array into k non-empty subsets whose sums are all equal.
Example 1: Input: nums = [4,3,2,3,5,2,1], k = 4 Output: true Explanation: It’s possible to divide it into 4 subsets (5), (1, 4), (2,3), (2,3) with equal sums.
Example 2: Input: nums = [1,2,3,4], k = 3 Output: false
Constraints: 1 <= k <= nums.length <= 16 1 <= nums[i] <= 104 The frequency of each element is in the range [1, 4].
classSolution: defcanPartitionKSubsets(self, nums: List[int], k: int) -> bool: defdfs(k, cur = 0, idx = 0): nonlocal ans if k == 1: ans = True return if cur == target: dfs(k - 1) for i inrange(idx, n): ifnot used[i] and cur + nums[i] <= target: used[i] = True dfs(k, cur + nums[i], i + 1) used[i] = False s = sum(nums) if s % k != 0: returnFalse target = s // k n = len(nums) nums.sort(reverse = True) used = [False] * n ans = False dfs(k) return ans
classSolution: defcanPartitionKSubsets(self, nums: List[int], k: int) -> bool: defdfs(idx): nonlocal ans if idx == n: ifall(v == target for v in ka): ans = True return for i inrange(k): if ka[i] + nums[idx] <= target: ka[i] += nums[idx] dfs(idx + 1) ka[i] -= nums[idx] s = sum(nums) if s % k != 0: returnFalse target = s // k ka = [0] * k n = len(nums) nums.sort(reverse = True) ans = False dfs(0) return ans
classSolution: defpermute(self, nums: List[int]) -> List[List[int]]: defdfs(): iflen(cur) == len(nums): ans.append(cur[:]) return for n in nums: if c[n] > 0: cur.append(n) c[n] -= 1 dfs() del cur[-1] c[n] += 1 c = Counter(nums) cur, ans = [], [] dfs() return ans
写法2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution: defpermute(self, nums): defdfs(): iflen(cur) == n: ans.append(cur[:]) return for i inrange(n): ifnot used[i]: used[i] = True cur.append(nums[i]) dfs() del cur[-1] used[i] = False cur, ans = [], [] n = len(nums) used = [False] * n dfs() return ans
11刷:高频, used = [False] * len(nums); def dfs(). subset从idx开始往后扫,全排每一位都有可能放任意数字,因此要从第一位往后扫。这样就需要一个used的变量来记住哪一位已经被用过了
classSolution: defpermuteUnique(self, nums: List[int]) -> List[List[int]]: defdfs(): iflen(cur) == n: ans.append(cur[:]) return for i inrange(n): if i and nums[i] == nums[i - 1] and used[i - 1]: continue ifnot used[i]: cur.append(nums[i]) used[i] = True dfs() del cur[-1] used[i] = False cur, ans = [], [] n = len(nums) used = [False] * n nums.sort() dfs() return ans
写法2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution: defpermuteUnique(self, nums): defdfs(): iflen(cur) == len(nums): ans.append(cur[:]) return for n in counter: if counter[n] > 0: cur.append(n) counter[n] -= 1 dfs() counter[n] += 1 del cur[-1] ans, cur = [], [] counter = Counter(nums) dfs() return ans
Given n pairs of parentheses, write a function to generate all combinations of well-formed parentheses.
For example, given n = 3, a solution set is: [ “((()))”, “(()())”, “(())()”, “()(())”, “()()()” ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution: defgenerateParenthesis(self, n: int) -> List[str]: defdfs(l, r): if l == r == n: ans.append(''.join(cur)) return if l < n: cur.append('(') dfs(l + 1, r) del cur[-1] if r < n and l > r: cur.append(')') dfs(l, r + 1) del cur[-1] ans, cur = [], [] dfs(0, 0) return ans
The n-queens puzzle is the problem of placing n queens on an n×n chessboard such that no two queens attack each other. Given an integer n, return all distinct solutions to the n-queens puzzle. Each solution contains a distinct board configuration of the n-queens' placement, where 'Q' and '.' both indicate a queen and an empty space respectively.
["..Q.", // Solution 2 "Q...", "...Q", ".Q.."] ] Explanation: There exist two distinct solutions to the 4-queens puzzle as shown above.
写法1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution: defsolveNQueens(self, n: int) -> List[List[str]]: defdfs(): nonlocal cur, ans iflen(cur) == n: ans.append(cur[:]) return for nC inrange(n): if nC notin cur andlen(cur) + nC notin [r + c for r, c inenumerate(cur)] andlen(cur) - nC notin [r - c for r, c inenumerate(cur)]: cur.append(nC) dfs() del cur[-1] cur, ans = [], [] dfs() return [['.' * i + 'Q' + '.' * (n - i - 1) for i in b] for b in ans]
classSolution: defsolveNQueens(self, n: int) -> List[List[str]]: defdfs(): iflen(cur) == n: ans.append(["." * i + "Q" + "." * (n - i - 1) for i in cur]) return for nC inrange(n): if nC notin cur and legal(nC): cur.append(nC) dfs() del cur[-1] deflegal(nC): nR = len(cur) for r, c inenumerate(cur): if nR + nC == r + c or nR - nC == r - c: returnFalse returnTrue cur, ans = [], [] dfs() return ans
6刷:高频。检查下一行的某列的合法性:举个栗子就能看出来,检查列就看此列是否已在cur中(皇后已在此列),检查/方向的对角线是坐标相加,检查\方向的对角线是坐标相减,行递增无需检查。时间:O(n^3), 空间:O(n)。因为c (count) 是row,v(value)是column, 正常 for c, v in enuerate() 就写成 for r, c in enumerate()
Given a string containing digits from 2-9 inclusive, return all possible letter combinations that the number could represent. A mapping of digit to letters (just like on the telephone buttons) is given below. Note that 1 does not map to any letters. Example: Input: “23” Output: [“ad”, “ae”, “af”, “bd”, “be”, “bf”, “cd”, “ce”, “cf”].
Note: Although the above answer is in lexicographical order, your answer could be in any order you want.
递归:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution: defletterCombinations(self, digits: str) -> List[str]: ifnot digits: return [] defdfs(idx): iflen(cur) == len(digits): ans.append("".join(cur)) return for c in kB[digits[idx]]: cur.append(c) dfs(idx + 1) del cur[-1] cur, ans = [], [] kB = {"2": "abc", "3": "def", "4": "ghi", "5": "jkl", "6": "mno", "7": "pqrs", "8": "tuv", "9": "wxyz"} dfs(0) return ans
遍历:
1 2 3 4 5 6 7 8 9
classSolution: defletterCombinations(self, digits: str) -> List[str]: ifnot digits: return [] kB = {'2': 'abc', '3': 'def', '4': 'ghi', '5': 'jkl', '6': 'mno', '7': 'pqrs', '8': 'tuv', '9': 'wxyz'} ans = [''] for i inrange(len(digits)): ans = [prev + c for prev in ans for c in kB[digits[i]]] return ans
Given a 2D board and a word, find if the word exists in the grid.
The word can be constructed from letters of sequentially adjacent cell, where "adjacent" cells are those horizontally or vertically neighboring. The same letter cell may not be used more than once.
classSolution: defexist(self, board: List[List[str]], word: str) -> bool: defdfs(r, c, idx): nonlocal ans if idx == len(word): ans = True return ifnot ans and0 <= r < m and0 <= c < n and board[r][c] == word[idx]: tmp = board[r][c] board[r][c] = '' for rD, cD in [(-1, 0), (1, 0), (0, -1), (0, 1)]: dfs(r + rD, c + cD, idx + 1) board[r][c] = tmp m, n = len(board), len(board[0]) ans = False for r inrange(m): for c inrange(n): ifnot ans: dfs(r, c, 0) return ans
Lintcode 787. The Maze There is a ball in a maze with empty spaces and walls. The ball can go through empty spaces by rolling up, down, left or right, but it won’t stop rolling until hitting a wall. When the ball stops, it could choose the next direction.
Given the ball’s start position, the destination and the maze, determine whether the ball could stop at the destination.
The maze is represented by a binary 2D array. 1 means the wall and 0 means the empty space. You may assume that the borders of the maze are all walls. The start and destination coordinates are represented by row and column indexes.
Output: false Explanation: There is no way for the ball to stop at the destination.
Note: 1.There is only one ball and one destination in the maze. 2.Both the ball and the destination exist on an empty space, and they will not be at the same position initially. 3.The given maze does not contain border (like the red rectangle in the example pictures), but you could assume the border of the maze are all walls. 4.The maze contains at least 2 empty spaces, and both the width and height of the maze won’t exceed 100.
Given an m x n matrix of non-negative integers representing the height of each unit cell in a continent, the “Pacific ocean” touches the left and top edges of the matrix and the “Atlantic ocean” touches the right and bottom edges. Water can only flow in four directions (up, down, left, or right) from a cell to another one with height equal or lower. Find the list of grid coordinates where water can flow to both the Pacific and Atlantic ocean.
Note: The order of returned grid coordinates does not matter. Both m and n are less than 150.
classSolution: defpacificAtlantic(self, matrix: List[List[int]]) -> List[List[int]]: defdfs(r, c, reach): reach[r][c] = 1 for rd, cd in [(-1, 0), (1, 0), (0, 1), (0, -1)]: nr, nc = r + rd, c + cd if0 <= nr <= m - 1and0 <= nc <= n - 1and heights[nr][nc] >= heights[r][c] andnot reach[nr][nc]: dfs(nr, nc, reach) m, n = len(heights), len(heights[0]) p, a = [[0] * n for _ inrange(m)], [[0] * n for _ inrange(m)] for r inrange(m): dfs(r, 0, p) dfs(r, n - 1, a) for c inrange(n): dfs(0, c, p) dfs(m - 1, c, a) return [[r, c] for r inrange(m) for c inrange(n) if p[r][c] == a[r][c] == 1]
classSolution: defpacificAtlantic(self, heights: List[List[int]]) -> List[List[int]]: m, n = len(heights), len(heights[0]) p, a = [[0] * n for _ inrange(m)], [[0] * n for _ inrange(m)] pq, aq = deque(), deque() for r inrange(m): p[r][0] = a[r][-1] = 1 pq.append((r, 0)) aq.append((r, n - 1)) for c inrange(n): p[0][c] = a[-1][c] = 1 pq.append((0, c)) aq.append((m - 1, c)) defbfs(q, reach): seen = set() while q: r, c = q.popleft() seen.add((r, c)) for dr, dc in [(-1, 0), (1, 0), (0, -1), (0, 1)]: nr, nc = r + dr, c + dc if0 <= nr < m and0 <= nc < n and heights[r][c] <= heights[nr][nc] and (nr, nc) notin seen: reach[nr][nc] = 1 q.append((nr, nc)) bfs(pq, p) bfs(aq, a) return [[r, c] for r inrange(m) for c inrange(n) if p[r][c] == a[r][c] == 1]
Equations are given in the format A / B = k, where A and B are variables represented as strings, and k is a real number (floating point number). Given some queries, return the answers. If the answer does not exist, return -1.0.
Example: Given a / b = 2.0, b / c = 3.0. queries are: a / c = ?, b / a = ?, a / e = ?, a / a = ?, x / x = ? . return [6.0, 0.5, -1.0, 1.0, -1.0 ].
The input is: vector<pair<string, string>> equations, vector& values, vector<pair<string, string>> queries , where equations.size() == values.size(), and the values are positive. This represents the equations. Return vector.
According to the example above: equations = [ [“a”, “b”], [“b”, “c”] ], values = [2.0, 3.0], queries = [ [“a”, “c”], [“b”, “a”], [“a”, “e”], [“a”, “a”], [“x”, “x”] ].
The input is always valid. You may assume that evaluating the queries will result in no division by zero and there is no contradiction.
classSolution: defcalcEquation(self, equations: List[List[str]], values: List[float], queries: List[List[str]]) -> List[float]: graph = collections.defaultdict(list) for [s, e], w inzip(equations, values): graph[s].append((e, w)) graph[e].append((s, 1 / w)) defdfs(s, e, cur): nonlocal res if s == e: res = cur return seen.add(s) for (n_s, w) in graph[s]: if n_s notin seen: dfs(n_s, e, cur * w) ans = [] for [s, e] in queries: seen = set() res = -1.0 if s in graph: dfs(s, e, 1.0) ans.append(res) return ans
classSolution: defcalcEquation(self, equations: List[List[str]], values: List[float], queries: List[List[str]]) -> List[float]: graph = collections.defaultdict(list) for [s, e], w inzip(equations, values): graph[s].append((e, w)) graph[e].append((s, 1 / w)) ans = [] for [s, e] in queries: res = -1.0 if s in graph: q = deque([(s, 1.0)]) seen = set() while q: c_s, cur = q.popleft() if c_s == e: res = cur break seen.add(c_s) for n_s, w in graph[c_s]: if n_s notin seen: q.append((n_s, w * cur)) ans.append(res) return ans
Given a list of airline tickets represented by pairs of departure and arrival airports [from, to], reconstruct the itinerary in order. All of the tickets belong to a man who departs from JFK. Thus, the itinerary must begin with JFK.
Note: If there are multiple valid itineraries, you should return the itinerary that has the smallest lexical order when read as a single string. For example, the itinerary [“JFK”, “LGA”] has a smaller lexical order than [“JFK”, “LGB”]. All airports are represented by three capital letters (IATA code). You may assume all tickets form at least one valid itinerary.
Example 2: Input: [[“JFK”,”SFO”],[“JFK”,”ATL”],[“SFO”,”ATL”],[“ATL”,”JFK”],[“ATL”,”SFO”]] Output: [“JFK”,”ATL”,”JFK”,”SFO”,”ATL”,”SFO”] Explanation: Another possible reconstruction is [“JFK”,”SFO”,”ATL”,”JFK”,”ATL”,”SFO”]. But it is larger in lexical order.
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: deffindItinerary(self, tickets: List[List[str]]) -> List[str]: graph = defaultdict(deque) for [s, e] insorted(tickets): graph[s].append(e) defdfs(s): while graph[s]: e = graph[s].popleft() dfs(e) ans.append(s) ans = [] dfs("JFK") return ans[::-1]
There are n cities. Some of them are connected, while some are not. If city a is connected directly with city b, and city b is connected directly with city c, then city a is connected indirectly with city c.
A province is a group of directly or indirectly connected cities and no other cities outside of the group.
You are given an n x n matrix isConnected where isConnected[i][j] = 1 if the ith city and the jth city are directly connected, and isConnected[i][j] = 0 otherwise.
Return the total number of provinces.
Example 1: Input: isConnected = [[1,1,0],[1,1,0],[0,0,1]] Output: 2
Example 2: Input: isConnected = [[1,0,0],[0,1,0],[0,0,1]] Output: 3
Constraints: 1 <= n <= 200 n == isConnected.length n == isConnected[i].length isConnected[i][j] is 1 or 0. isConnected[i][i] == 1 isConnected[i][j] == isConnected[j][i]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: deffindCircleNum(self, isConnected: List[List[int]]) -> int: defdfs(i): for j, conn inenumerate(isConnected[i]): if conn and j notin seen: seen.add(j) dfs(j) seen = set() ans = 0 for i inrange(len(isConnected)): if i notin seen: seen.add(i) dfs(i) ans += 1 return ans
Given two sorted integer arrays nums1 and nums2, merge nums2 into nums1 as one sorted array.
Note:
The number of elements initialized in nums1 and nums2 are m and n respectively. You may assume that nums1 has enough space (size that is greater or equal to m + n) to hold additional elements from nums2. Example:
Input: nums1 = [1,2,3,0,0,0], m = 3 nums2 = [2,5,6], n = 3
Output: [1,2,2,3,5,6]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defmerge(self, nums1: List[int], m: int, nums2: List[int], n: int) -> None: m -= 1 n -= 1 p = len(nums1) - 1 while m >= 0and n >= 0: if nums1[m] < nums2[n]: nums1[p] = nums2[n] n -= 1 else: nums1[p] = nums1[m] m -= 1 p -= 1 if n >= 0: nums1[:p + 1] = nums2[:n + 1]
A straight forward solution using O(mn) space is probably a bad idea. A simple improvement uses O(m + n) space, but still not the best solution. Could you devise a constant space solution?
classSolution: defsetZeroes(self, matrix: List[List[int]]) -> None: is1stRZ, is1stCZ = Trueif0in matrix[0] elseFalse, Trueif0inlist(zip(*matrix))[0] elseFalse for i, r inenumerate(matrix): for j, c inenumerate(r): if i and j and c == 0: matrix[i][0] = 0 matrix[0][j] = 0 m, n = len(matrix), len(matrix[0]) for i inrange(1, m): if matrix[i][0] == 0: matrix[i] = [0] * n for j inrange(1, n): if matrix[0][j] == 0: for i inrange(1, m): matrix[i][j] = 0 if is1stRZ: matrix[0] = [0] * n if is1stCZ: for i inrange(m): matrix[i][0] = 0
Given a collection of intervals, merge all overlapping intervals.
Example 1:
Input: [[1,3],[2,6],[8,10],[15,18]] Output: [[1,6],[8,10],[15,18]] Explanation: Since intervals [1,3] and [2,6] overlaps, merge them into [1,6]. Example 2:
Input: [[1,4],[4,5]] Output: [[1,5]] Explanation: Intervals [1,4] and [4,5] are considered overlapping.
高频
1 2 3 4 5 6 7 8 9 10 11 12
classSolution: defmerge(self, intervals: List[List[int]]) -> List[List[int]]: intervals.sort(key = lambda x: x[0]) cur, ans = intervals[0], [] for it in intervals[1:]: if it[0] <= cur[1]: cur[1] = max(cur[1], it[1]) else: ans.append(cur) cur = it ans.append(cur) return ans
Merge two sorted (ascending) lists of interval and return it as a new sorted list. The new sorted list should be made by splicing together the intervals of the two lists and sorted in ascending order.
The intervals in the given list do not overlap. The intervals in different lists may overlap. Example Given list1 = [(1,2),(3,4)] and list2 = [(2,3),(5,6)], return [(1,4),(5,6)].
""" Definition of Interval. class Interval(object): def __init__(self, start, end): self.start = start self.end = end """ classSolution: """ @param list1: one of the given list @param list2: another list @return: the new sorted list of interval """ defmergeTwoInterval(self, list1, list2): # write your code here ifnot list1: return list2 ifnot list2: return list1 list3 = list1 + list2 list3.sort(key=lambda x: x.start) ans = [list3[0]] for i inrange(1, len(list3)): if list3[i].start <= ans[-1].end: ans[-1].end = max(list3[i].end, ans[-1].end) else: ans.append(list3[i]) return ans
classSolution: defaddBinary(self, a: str, b: str) -> str: m = len(a) n = len(b) l = max(m, n) i = 1 carry = 0 ans = "" while i <= l: if i <= m and i <= n: val = int(a[-i]) + int(b[-i]) + carry elif i <= m: val = int(a[-i]) + carry elif i <= n: val = int(b[-i]) + carry if val > 1: carry = 1 else: carry = 0 ans = str(val % 2) + ans i += 1 if carry == 1: ans = "1" + ans return ans
总结:…i = 1…while i **<=** l:…if val > 1: carry = 1; else: carry = 0; ans = str(val % 2) + ans; i += 1…
Roman numerals are represented by seven different symbols: I, V, X, L, C, D and M.
Symbol Value I 1 V 5 X 10 L 50 C 100 D 500 M 1000 For example, two is written as II in Roman numeral, just two one's added together. Twelve is written as, XII, which is simply X + II. The number twenty seven is written as XXVII, which is XX + V + II.
Roman numerals are usually written largest to smallest from left to right. However, the numeral for four is not IIII. Instead, the number four is written as IV. Because the one is before the five we subtract it making four. The same principle applies to the number nine, which is written as IX. There are six instances where subtraction is used:
I can be placed before V (5) and X (10) to make 4 and 9. X can be placed before L (50) and C (100) to make 40 and 90. C can be placed before D (500) and M (1000) to make 400 and 900. Given an integer, convert it to a roman numeral. Input is guaranteed to be within the range from 1 to 3999.
Example 1:
Input: 3 Output: "III" Example 2:
Input: 4 Output: "IV" Example 3:
Input: 9 Output: "IX" Example 4:
Input: 58 Output: "LVIII" Explanation: L = 50, V = 5, III = 3. Example 5:
Input: 1994 Output: "MCMXCIV" Explanation: M = 1000, CM = 900, XC = 90 and IV = 4.
高频
1 2 3 4 5 6 7 8 9 10 11 12
classSolution: defintToRoman(self, num: int) -> str: n = [1000, 900, 500, 400, 100, 90, 50, 40, 10, 9, 5, 4, 1] l = ["M", "CM", "D", "CD", "C", "XC", "L", "XL", "X", "IX", "V", "IV", "I"] ans = "" for i, v inenumerate(n): if num == 0: return ans t = num // v ans += l[i] * t num %= v return ans
The length of both num1 and num2 is < 110. Both num1 and num2 contain only digits 0-9. Both num1 and num2 do not contain any leading zero, except the number 0 itself. You must not use any built-in BigInteger library or convert the inputs to integer directly.
Given an unsorted array of integers, find the length of the longest consecutive elements sequence.
Your algorithm should run in O(n) complexity.
Example:
Input: [100, 4, 200, 1, 3, 2] Output: 4 Explanation: The longest consecutive elements sequence is [1, 2, 3, 4]. Therefore its length is 4.
1 2 3 4 5 6 7 8 9 10 11
classSolution: deflongestConsecutive(self, nums: List[int]) -> int: nums = set(nums) ans = 0 for n in nums: if n - 1notin nums: m = n + 1 while m in nums: m += 1 ans = max(ans, m - n) return ans
Given a non-empty array of digits representing a non-negative integer, plus one to the integer.
The digits are stored such that the most significant digit is at the head of the list, and each element in the array contain a single digit.
You may assume the integer does not contain any leading zero, except the number 0 itself.
Example 1:
Input: [1,2,3] Output: [1,2,4] Explanation: The array represents the integer 123. Example 2:
Input: [4,3,2,1] Output: [4,3,2,2] Explanation: The array represents the integer 4321.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defplusOne(self, digits: List[int]) -> List[int]: digits.reverse() c = 0 for i, d inenumerate(digits): if i == 0: d += 1 else: d += c c = d // 10 d = d % 10 digits[i] = d if c > 0: digits.append(1) return digits[::-1]
Determine whether an integer is a palindrome. An integer is a palindrome when it reads the same backward as forward.
Example 1:
Input: 121 Output: true Example 2:
Input: -121 Output: false Explanation: From left to right, it reads -121. From right to left, it becomes 121-. Therefore it is not a palindrome. Example 3:
Input: 10 Output: false Explanation: Reads 01 from right to left. Therefore it is not a palindrome. Follow up:
Coud you solve it without converting the integer to a string?
1 2 3 4 5 6 7 8 9 10 11
classSolution: defisPalindrome(self, x: int) -> bool: if x < 0: returnFalse ox = x nx = 0 while x: ln = x % 10 nx = nx * 10 + ln x //= 10 return nx == ox
classSolution: defgenerateMatrix(self, n: int) -> List[List[int]]: ans = [[0] * n for _ inrange(n)] mode, r, c, circle = 0, 0, 0, 0 for i inrange(1, n * n + 1): ans[r][c] = i if mode == 0: c += 1 if c == n - 1 - circle: mode = 1 elif mode == 1: r += 1 if r == n - 1 - circle: mode = 2 elif mode == 2: c -= 1 if c == circle: mode = 3 else: r -= 1 if r == circle + 1: mode = 0 circle += 1 return ans
高频:…if c == n - 1 - circle:…if r == n - 1 - circle:…if c == circle:…if r = circle + 1:…
You are given an n x n 2D matrix representing an image. Rotate the image by 90 degrees (clockwise). Note: You have to rotate the image in-place, which means you have to modify the input 2D matrix directly. DO NOT allocate another 2D matrix and do the rotation.
Example 1: Given input matrix = [ [1,2,3], [4,5,6], [7,8,9] ],
rotate the input matrix in-place such that it becomes: [ [7,4,1], [8,5,2], [9,6,3] ] Example 2:
rotate the input matrix in-place such that it becomes: [ [15,13, 2, 5], [14, 3, 4, 1], [12, 6, 8, 9], [16, 7,10,11] ]
对角线翻转后左右翻转:
1 2 3 4 5 6 7 8 9
classSolution: defrotate(self, matrix: List[List[int]]) -> None: n = len(matrix) for r inrange(n): for c inrange(r + 1, n): matrix[r][c], matrix[c][r] = matrix[c][r], matrix[r][c] for r inrange(n): for c inrange(n // 2): matrix[r][c], matrix[r][n - 1 - c] = matrix[r][n - 1 - c], matrix[r][c]
上下翻转后对角线翻转:
1 2 3 4 5 6 7
classSolution: defrotate(self, matrix: List[List[int]]) -> None: n = len(matrix) matrix.reverse() for r inrange(n): for c inrange(r + 1, n): matrix[r][c], matrix[c][r] = matrix[c][r], matrix[r][c]
classSolution: defspiralOrder(self, matrix: List[List[int]]) -> List[int]: R, D, L, U = (0, 1), (1, 0), (0, -1), (-1, 0) ans = [] m, n = len(matrix) - 1, len(matrix[0]) - 1 r, c, direction, cir = 0, 0, R, 0 for _ inrange((m + 1) * (n + 1)): ans.append(matrix[r][c]) if direction == R and c + cir == n: direction = D elif direction == D and r + cir == m: direction = L elif direction == L and c == cir: direction = U elif direction == U and r == cir + 1: direction = R cir += 1 r += direction[0] c += direction[1] return ans
Given an array of words and a width maxWidth, format the text such that each line has exactly maxWidth characters and is fully (left and right) justified.
You should pack your words in a greedy approach; that is, pack as many words as you can in each line. Pad extra spaces ' ' when necessary so that each line has exactly maxWidth characters.
Extra spaces between words should be distributed as evenly as possible. If the number of spaces on a line do not divide evenly between words, the empty slots on the left will be assigned more spaces than the slots on the right.
For the last line of text, it should be left justified and no extra space is inserted between words.
Note:
A word is defined as a character sequence consisting of non-space characters only. Each word's length is guaranteed to be greater than 0 and not exceed maxWidth. The input array words contains at least one word. Example 1:
Input: words = ["This", "is", "an", "example", "of", "text", "justification."] maxWidth = 16 Output: [ "This is an", "example of text", "justification. " ] Example 2:
Input: words = ["What","must","be","acknowledgment","shall","be"] maxWidth = 16 Output: [ "What must be", "acknowledgment ", "shall be " ] Explanation: Note that the last line is "shall be " instead of "shall be", because the last line must be left-justified instead of fully-justified. Note that the second line is also left-justified becase it contains only one word. Example 3:
Input: words = ["Science","is","what","we","understand","well","enough","to","explain", "to","a","computer.","Art","is","everything","else","we","do"] maxWidth = 20 Output: [ "Science is what we", "understand well", "enough to explain to", "a computer. Art is", "everything else we", "do " ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution: deffullJustify(self, words: List[str], maxWidth: int) -> List[str]: ans, line, letter_count = [], [], 0 for w in words: if letter_count + len(w) + len(line) > maxWidth: for i inrange(maxWidth - letter_count): line[i % (len(line) - 1or1)] += ' ' ans.append(''.join(line)) line = [] letter_count = 0 line += [w] letter_count += len(w) ans.append(' '.join(line).ljust(maxWidth)) return ans
Determine if a 9x9 Sudoku board is valid. Only the filled cells need to be validated according to the following rules: Each row must contain the digits 1-9 without repetition. Each column must contain the digits 1-9 without repetition. Each of the 9 3x3 sub-boxes of the grid must contain the digits 1-9 without repetition. A partially filled sudoku which is valid. The Sudoku board could be partially filled, where empty cells are filled with the character ‘.’.
Example 2: Input: [ ["8","3",".",".","7",".",".",".","."], ["6",".",".","1","9","5",".",".","."], [".","9","8",".",".",".",".","6","."], ["8",".",".",".","6",".",".",".","3"], ["4",".",".","8",".","3",".",".","1"], ["7",".",".",".","2",".",".",".","6"], [".","6",".",".",".",".","2","8","."], [".",".",".","4","1","9",".",".","5"], [".",".",".",".","8",".",".","7","9"] ] Output: false Explanation: Same as Example 1, except with the 5 in the top left corner being modified to 8. Since there are two 8's in the top left 3x3 sub-box, it is invalid.
Note: A Sudoku board (partially filled) could be valid but is not necessarily solvable. Only the filled cells need to be validated according to the mentioned rules. The given board contain only digits 1-9 and the character ‘.’. The given board size is always 9x9.
classSolution: defisValidSudoku(self, board: List[List[str]]) -> bool: defvalidate(r): s = set() for c in r: if c in s: returnFalse if c != '.': s.add(c) returnTrue ifany((not validate(r) for r in board)): returnFalse ifany((not validate(c) for c inzip(*board))): returnFalse for r inrange(0, 9, 3): for c inrange(0, 9, 3): sb = [] for i inrange(3): for j inrange(3): sb.append(board[r + i][c + j]) ifnot validate(sb): returnFalse returnTrue
The count-and-say sequence is the sequence of integers with the first five terms as following:
1. 1 2. 11 3. 21 4. 1211 5. 111221 1 is read off as "one 1" or 11. 11 is read off as "two 1s" or 21. 21 is read off as "one 2, then one 1" or 1211.
Given an integer n where 1 ≤ n ≤ 30, generate the nth term of the count-and-say sequence. Note: Each term of the sequence of integers will be represented as a string.
Example 1:
Input: 1 Output: "1" Example 2:
Input: 4 Output: "1211"
用itertools.groupby():
1 2 3 4 5 6 7 8 9 10
classSolution: defcountAndSay(self, n: int) -> str: ans = "1" for i inrange(n - 1): t = "" for d, g in itertools.groupby(ans): cnt = len(list(g)) t += str(cnt) + str(d) ans = t return ans
不用groupby:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defcountAndSay(self, n: int) -> str: ans = "1" for i inrange(n - 1): res = "" t = ans + "#" cnt = 1 for i inrange(len(t) - 1): if t[i] == t[i + 1]: cnt += 1 else: res += str(cnt) + t[i] cnt = 1 ans = res return ans
高频:题目描述不是很清楚,用groupby:…for d, g in itertools.groupby():…。不用groupby:…res = “”; t = ans + “#”…
Given a non-negative index k where k ≤ 33, return the kth index row of the Pascal's triangle. Note that the row index starts from 0. In Pascal's triangle, each number is the sum of the two numbers directly above it.
Example: Input: 3 Output: [1,3,3,1]
Follow up: Could you optimize your algorithm to use only O(k) extra space?
1 2 3 4 5 6
classSolution: defgetRow(self, rowIndex: int) -> List[int]: ans = [1] for i inrange(rowIndex): ans = [x + y for x, y inzip(ans + [0], [0] + ans)] return ans
高频:很巧妙的…[x + y for x, y in zip(ans + [0], [0] + ans)]…
The string "PAYPALISHIRING" is written in a zigzag pattern on a given number of rows like this: (you may want to display this pattern in a fixed font for better legibility)
P A H N A P L S I I G Y I R And then read line by line: "PAHNAPLSIIGYIR"
Write the code that will take a string and make this conversion given a number of rows:
string convert(string s, int numRows); Example 1:
Input: s = "PAYPALISHIRING", numRows = 3 Output: "PAHNAPLSIIGYIR" Example 2:
Input: s = "PAYPALISHIRING", numRows = 4 Output: "PINALSIGYAHRPI" Explanation:
P I N A L S I G Y A H R P I
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution: defconvert(self, s: str, numRows: int) -> str: if numRows == 1: return s res = [''] * numRows r, d = 0, 1 for c in s: res[r] += c if r == 0: d = 1 if r == numRows - 1: d = -1 r += d return''.join(res)
Implement atoi which converts a string to an integer.
The function first discards as many whitespace characters as necessary until the first non-whitespace character is found. Then, starting from this character, takes an optional initial plus or minus sign followed by as many numerical digits as possible, and interprets them as a numerical value.
The string can contain additional characters after those that form the integral number, which are ignored and have no effect on the behavior of this function.
If the first sequence of non-whitespace characters in str is not a valid integral number, or if no such sequence exists because either str is empty or it contains only whitespace characters, no conversion is performed.
If no valid conversion could be performed, a zero value is returned.
Note:
Only the space character ' ' is considered as whitespace character. Assume we are dealing with an environment which could only store integers within the 32-bit signed integer range: [−231, 231 − 1]. If the numerical value is out of the range of representable values, INT_MAX (231 − 1) or INT_MIN (−231) is returned. Example 1:
Input: "42" Output: 42 Example 2:
Input: " -42" Output: -42 Explanation: The first non-whitespace character is '-', which is the minus sign. Then take as many numerical digits as possible, which gets 42. Example 3:
Input: "4193 with words" Output: 4193 Explanation: Conversion stops at digit '3' as the next character is not a numerical digit. Example 4:
Input: "words and 987" Output: 0 Explanation: The first non-whitespace character is 'w', which is not a numerical digit or a +/- sign. Therefore no valid conversion could be performed. Example 5:
Input: "-91283472332" Output: -2147483648 Explanation: The number "-91283472332" is out of the range of a 32-bit signed integer. Thefore INT_MIN (−231) is returned.
classSolution: defmyAtoi(self, str: str) -> int: return self.helper(str) defhelper(self, s): s = s.strip() ifnot s: return0 valid = [str(i) for i inrange(10)] signs = '+-' if s[0] notin valid and s[0] notin signs: return0 sign = 1 if s[0] == '-': sign = -1 if s[0] in signs: s = s[1:] ans = '' for l in s: if l in valid: ans += l if sign == -1and -int(ans) < -pow(2, 31): return -pow(2, 31) if sign == 1andint(ans) > pow(2, 31) - 1: returnpow(2, 31) - 1 else: return sign * int(ans) if ans else0 return sign * int(ans) if ans else0
Input: intervals = [[1,2],[3,5],[6,7],[8,10],[12,16]], newInterval = [4,8] Output: [[1,2],[3,10],[12,16]] Explanation: Because the new interval [4,8] overlaps with [3,5],[6,7],[8,10]. NOTE: input types have been changed on April 15, 2019. Please reset to default code definition to get new method signature.
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: definsert(self, intervals: List[List[int]], newInterval: List[int]) -> List[List[int]]: left, right = [], [] ns, ne = newInterval[0], newInterval[1] for i, [s, e] inenumerate(intervals): if e < ns: left.append([s, e]) elif ne < s: right.append([s, e]) else: ns = min(ns, s) ne = max(ne, e) return left + [[ns, ne]] + right
写法2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution: definsert(self, intervals: List[List[int]], newInterval: List[int]) -> List[List[int]]: ans = [] i = 0 ns, ne = newInterval[0], newInterval[1] n = len(intervals) while i < n and intervals[i][1] < ns: ans.append(intervals[i]) i += 1 while i < n and intervals[i][0] <= ne: ns = min(ns, intervals[i][0]) ne = max(ne, intervals[i][1]) i += 1 ans.append([ns, ne]) while i < n: ans.append(intervals[i]) i += 1 return ans
You have an array of logs. Each log is a space delimited string of words.
For each log, the first word in each log is an alphanumeric identifier. Then, either:
Each word after the identifier will consist only of lowercase letters, or; Each word after the identifier will consist only of digits. We will call these two varieties of logs letter-logs and digit-logs. It is guaranteed that each log has at least one word after its identifier.
Reorder the logs so that all of the letter-logs come before any digit-log. The letter-logs are ordered lexicographically ignoring identifier, with the identifier used in case of ties. The digit-logs should be put in their original order.
Given an array, rotate the array to the right by k steps, where k is non-negative.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Example 1: Input: [1,2,3,4,5,6,7] and k = 3 Output: [5,6,7,1,2,3,4] Explanation: rotate 1 steps to the right: [7,1,2,3,4,5,6] rotate 2 steps to the right: [6,7,1,2,3,4,5] rotate 3 steps to the right: [5,6,7,1,2,3,4]
Example 2: Input: [-1,-100,3,99] and k = 2 Output: [3,99,-1,-100] Explanation: rotate 1 steps to the right: [99,-1,-100,3] rotate 2 steps to the right: [3,99,-1,-100]
Note: Try to come up as many solutions as you can, there are at least 3 different ways to solve this problem. Could you do it in-place with O(1) extra space?
O(n) space:
1 2 3 4 5 6
classSolution: defrotate(self, nums: List[int], k: int) -> None: n = len(nums) original = nums[:] for i inrange(n): nums[(i + k) % n] = original[i]
O(1) space:
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: defrotate(self, nums: List[int], k: int) -> None: k = k % len(nums) if k == 0orlen(nums) == 1: return nums.reverse() self.reverse(nums, 0, k - 1) self.reverse(nums, k, len(nums) - 1) defreverse(self, nums, s, e): while s < e: nums[s], nums[e] = nums[e], nums[s] s += 1 e -= 1
LinC 912. Best Meeting Point A group of two or more people wants to meet and minimize the total travel distance. You are given a 2D grid of values 0 or 1, where each 1 marks the home of someone in the group. The distance is calculated using Manhattan Distance, where distance(p1, p2) = |p2.x - p1.x| + |p2.y - p1.y|.
Example 1: Input: [[1,0,0,0,1],[0,0,0,0,0],[0,0,1,0,0]] Output: 6 Explanation: The point (0,2) is an ideal meeting point, as the total travel distance of 2 + 2 + 2 = 6 is minimal. So return 6.
Example 2: Input: [[1,1,0,0,1],[1,0,1,0,0],[0,0,1,0,1]] Output: 14
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution: defminTotalDistance(self, grid): rows, cols = [], [] for r inrange(len(grid)): for c inrange(len(grid[0])): if grid[r][c] == 1: rows.append(r) cols.append(c) rows.sort() cols.sort() ans = 0 i, j = 0, len(rows) - 1 while i < j: ans += rows[j] - rows[i] + cols[j] - cols[i] i += 1 j -= 1 return ans
Given a string s and a non-empty string p, find all the start indices of p’s anagrams in s. Strings consists of lowercase English letters only and the length of both strings s and p will not be larger than 20,100. The order of output does not matter.
Example 1: Input: s: “cbaebabacd” p: “abc” Output: [0, 6] Explanation: The substring with start index = 0 is “cba”, which is an anagram of “abc”. The substring with start index = 6 is “bac”, which is an anagram of “abc”.
Example 2: Input: s: “abab” p: “ab” Output: [0, 1, 2] Explanation: The substring with start index = 0 is “ab”, which is an anagram of “ab”. The substring with start index = 1 is “ba”, which is an anagram of “ab”. The substring with start index = 2 is “ab”, which is an anagram of “ab”.
classSolution: deffindAnagrams(self, s: str, p: str) -> List[int]: pc = Counter(p) cnt = len(pc) n = len(p) ans = [] i = j = 0 while j < len(s): if s[j] in pc: pc[s[j]] -= 1 if pc[s[j]] == 0: cnt -= 1 j += 1 while cnt == 0: if s[i] in pc: pc[s[i]] += 1 if pc[s[i]] == 1: cnt += 1 if j - i == n: ans.append(i) i += 1 return ans
写法2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: deffindAnagrams(self, s: str, p: str) -> List[int]: pc = Counter(p) sc = Counter() n = len(p) ans = [] for i inrange(len(s)): if i > n - 1: sc[s[i - n]] -= 1 if sc[s[i - n]] == 0: del sc[s[i - n]] sc[s[i]] += 1 if sc == pc: ans.append(i - n + 1) return ans
Given a string, find the length of the longest substring without repeating characters.
Example 1: Input: “abcabcbb” Output: 3 Explanation: The answer is “abc”, with the length of 3.
Example 2: Input: “bbbbb” Output: 1 Explanation: The answer is “b”, with the length of 1.
Example 3: Input: “pwwkew” Output: 3 Explanation: The answer is “wke”, with the length of 3. Note that the answer must be a substring, “pwke” is a subsequence and not a substring.
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: deflengthOfLongestSubstring(self, s: str) -> int: i = j = 0 ans = 0 c = Counter() while j < len(s): c[s[j]] += 1 whileany(v > 1for v in c.values()): c[s[i]] -= 1 i += 1 ans = max(ans, j - i + 1) j += 1 return ans
Given a string S and a string T, find the minimum window in S which will contain all the characters in T in complexity O(n).
Example: Input: S = “ADOBECODEBANC”, T = “ABC” Output: “BANC”
Note: If there is no such window in S that covers all characters in T, return the empty string “”. If there is such window, you are guaranteed that there will always be only one unique minimum window in S.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution: defminWindow(self, s: str, t: str) -> str: c = Counter(t) i = j = 0 cnt = len(t) res = None while j < len(s): if c[s[j]] > 0: cnt -= 1 c[s[j]] -= 1 while cnt == 0: ifnot res or j - i < res[1] - res[0]: res = (i, j) c[s[i]] += 1 if c[s[i]] > 0: cnt += 1 i += 1 j += 1 return s[res[0]:res[1] + 1] if res else""
Given an array of positive integers nums and a positive integer target, return the minimal length of a contiguous subarray [numsl, numsl+1, …, numsr-1, numsr] of which the sum is greater than or equal to target. If there is no such subarray, return 0 instead.
Example 1: Input: target = 7, nums = [2,3,1,2,4,3] Output: 2 Explanation: The subarray [4,3] has the minimal length under the problem constraint.
geeks for geeks article Given an array of 0’s and 1’s, we need to write a program to find the minimum number of swaps required to group all 1’s present in the array together.
Examples: Input : arr[] = {1, 0, 1, 0, 1} Output : 1 Explanation: Only 1 swap is required to group all 1’s together. Swapping index 1 and 4 will give arr[] = {1, 1, 1, 0, 0}
Input : arr[] = {1, 0, 1, 0, 1, 1} Output : 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
defminSwaps(arr): from collections import Counter counter = Counter(arr) targetLen = counter[1] counter = Counter(arr[0:targetLen]) most1s = counter[1] for i inrange(1, len(arr) - targetLen + 1): #because I already know how many 1s in previous subarray. Just add or subtract as I go if boxes[i - 1] == 1: counter[1] -= 1 if boxes[i + targetLen - 1] == 1: counter[1] += 1 if counter[1] > most1s: most1s = counter[1] return targetLen - most1s
面经:Celo。算法的核心是:find the subarray of counter[1] length that has the most 1’s. Then just move the 1’s from elsewhere to fill the 0’s in this subarray
Given an array A of 0s and 1s, we may change up to K values from 0 to 1. Return the length of the longest (contiguous) subarray that contains only 1s.
Example 1: Input: A = [1,1,1,0,0,0,1,1,1,1,0], K = 2 Output: 6 Explanation: [1,1,1,0,0,1,1,1,1,1,1] Bolded numbers were flipped from 0 to 1. The longest subarray is underlined.
Example 2: Input: A = [0,0,1,1,0,0,1,1,1,0,1,1,0,0,0,1,1,1,1], K = 3 Output: 10 Explanation: [0,0,1,1,1,1,1,1,1,1,1,1,0,0,0,1,1,1,1] Bolded numbers were flipped from 0 to 1. The longest subarray is underlined.
Note: 1 <= A.length <= 20000 0 <= K <= A.length A[i] is 0 or 1
1 2 3 4 5 6 7 8 9
classSolution: deflongestOnes(self, A: List[int], K: int) -> int: l = 0 for r inrange(len(A)): K -= 1 - A[r] if K < 0: K += 1 - A[l] l += 1 return r - l + 1
一刷:Facebook tag
Linked List 链表
[83. Remove Duplicates from Sorted List (Easy)](83. Remove Duplicates from Sorted List)
Given a sorted linked list, delete all duplicates such that each element appear only once.
Example 1: Input: 1->1->2 Output: 1->2
Example 2: Input: 1->1->2->3->3 Output: 1->2->3
高频
1 2 3 4 5 6 7 8 9
classSolution: defdeleteDuplicates(self, head: ListNode) -> ListNode: cur = head while cur and cur.next: if cur.val == cur.next.val: cur.next = cur.next.next else: cur = cur.next return head
总结:…temp = head; while temp and temp.next: …temp.next = temp.next.next; else: temp = temp.next…
Given a linked list, remove the n-th node from the end of list and return its head.
Example: Given linked list: 1->2->3->4->5, and n = 2. After removing the second node from the end, the linked list becomes 1->2->3->5.
Note: Given n will always be valid.
Follow up: Could you do this in one pass?
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: defremoveNthFromEnd(self, head: ListNode, n: int) -> ListNode: dummy = ListNode(0) dummy.next = head fast = slow = dummy while n: n -= 1 fast = fast.next while fast and fast.next: fast = fast.next slow = slow.next slow.next = slow.next.next return dummy.next
You are given two non-empty linked lists representing two non-negative integers. The digits are stored in reverse order and each of their nodes contain a single digit. Add the two numbers and return it as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
classSolution: defaddTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]: defl2n(n): res = '' while n: res = str(n.val) + res n = n.next returnint(res) defn2l(n): head = None n = str(n) for d in n: cur = ListNode(d) ifnot head: head = cur else: tmp = head head = cur cur.next = tmp return head return n2l(l2n(l1) + l2n(l2))
defl2n(n): res, d = 0, 0 while n: res += n.val * (10 ** d) d += 1 n = n.next return res defn2l(n): res = prev = None if n == 0: return ListNode(0) while n: cur = ListNode(n % 10) ifnot res: res = prev = cur else: prev.next = cur prev = cur n //= 10 return res return n2l(l2n(l1) + l2n(l2))
You are given two non-empty linked lists representing two non-negative integers. The most significant digit comes first and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
Constraints: The number of nodes in each linked list is in the range [1, 100]. 0 <= Node.val <= 9 It is guaranteed that the list represents a number that does not have leading zeros.
Follow up: Could you solve it without reversing the input lists?
classSolution: defaddTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]: s1, s2 = [], [] while l1: s1.append(l1.val) l1 = l1.next while l2: s2.append(l2.val) l2 = l2.next p = ListNode(0) s = 0 while s1 or s2: if s1: s += s1.pop() if s2: s += s2.pop() p.val = s % 10 t = ListNode(s // 10) t.next = p p = t s //= 10 return p.nextif p.val == 0else p
Given a linked list and a value x, partition it such that all nodes less than x come before nodes greater than or equal to x. You should preserve the original relative order of the nodes in each of the two partitions.
Example: Input: head = 1->4->3->2->5->2, x = 3 Output: 1->2->2->4->3->5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defpartition(self, head: ListNode, x: int) -> ListNode: loHead = loDummy = ListNode(0) hiHead = hiDummy = ListNode(0) while head: if head.val < x: loHead.next = head loHead = loHead.next else: hiHead.next = head hiHead = hiHead.next head = head.next loHead.next = hiDummy.next hiHead.next = None return loDummy.next
Given a linked list, determine if it has a cycle in it. To represent a cycle in the given linked list, we use an integer pos which represents the position (0-indexed) in the linked list where tail connects to. If pos is -1, then there is no cycle in the linked list.
Example 1: Input: head = [3,2,0,-4], pos = 1 Output: true Explanation: There is a cycle in the linked list, where tail connects to the second node.
Example 2: Input: head = [1,2], pos = 0 Output: true Explanation: There is a cycle in the linked list, where tail connects to the first node.
Example 3: Input: head = [1], pos = -1 Output: false Explanation: There is no cycle in the linked list.
Follow up: Can you solve it without using extra space?
1 2 3 4 5 6 7 8 9 10 11
classSolution(object): defhasCycle(self, head): ifnot head: returnFalse s = f = head while f.nextand f.next.next: s = s.next f = f.next.next if s == f: returnTrue returnFalse
Given a linked list, return the node where the cycle begins. If there is no cycle, return null. To represent a cycle in the given linked list, we use an integer pos which represents the position (0-indexed) in the linked list where tail connects to. If pos is -1, then there is no cycle in the linked list. Note: Do not modify the linked list.
Example 1: Input: head = [3,2,0,-4], pos = 1 Output: tail connects to node index 1 Explanation: There is a cycle in the linked list, where tail connects to the second node.
Example 2: Input: head = [1,2], pos = 0 Output: tail connects to node index 0 Explanation: There is a cycle in the linked list, where tail connects to the first node.
Example 3: Input: head = [1], pos = -1 Output: no cycle Explanation: There is no cycle in the linked list.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution(object): defdetectCycle(self, head): ifnot head ornot head.next: return s = f = head loop = False while f.nextand f.next.next: s = s.next f = f.next.next if s == f: loop = True break ifnot loop: return s = head while s != f: s = s.next f = f.next return s
面经:维萨。关键知识点是1.相遇点是慢指针在环里的 第一圈。是快指针在环里的第n圈。2. 慢指针走了x+y, 快指针走了 2(x + y) 3. 快指针这个 距离又等同于 x + y + nr 4. x = nr - y 4. 由下图可见, nr - y = z 5. z 和 x 是相等的。 6. 因此可以head与快或慢同时前进,相遇即是B点。
1 2 3 4 5 6 7
x y A ------ B --------+ | | z | | +----C----+ * 环的长度为 r * C: 快慢指针相遇点
classSolution: defreverseBetween(self, head: ListNode, m: int, n: int) -> ListNode: pre = dummy = ListNode(0) dummy.next = head i = 0 while i < m - 1: pre = pre.next head = head.next i += 1 first = p = head head = head.next while i < n - 1: t = head.next head.next = p p = head head = t i += 1 pre.next = p first.next = head return dummy.next
Write a program to find the node at which the intersection of two singly linked lists begins. For example, the following two linked lists:
1 2 3 4 5
A: a1 → a2 ↘ c1 → c2 → c3 ↗ B: b1 → b2 → b3
begin to intersect at node c1.
Notes: If the two linked lists have no intersection at all, return null. The linked lists must retain their original structure after the function returns. You may assume there are no cycles anywhere in the entire linked structure. Your code should preferably run in O(n) time and use only O(1) memory.
Given a linked list, swap every two adjacent nodes and return its head. You may not modify the values in the list’s nodes, only nodes itself may be changed.
Example: Given 1->2->3->4, you should return the list as 2->1->4->3.
高频
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: defswapPairs(self, head: ListNode) -> ListNode: dummy = cur = ListNode(0) while head and head.next: a, b = head, head.next head = b.next cur.next = b b.next = a cur = a cur.next = None if head: cur.next = head return dummy.next
递归
1 2 3 4 5 6 7 8 9
classSolution: defswapPairs(self, head: ListNode) -> ListNode: ifnot head ornot head.next: return head neighbor = head.next frontier = neighbor.next neighbor.next = head head.next = self.swapPairs(frontier) return neighbor
Given a linked list, rotate the list to the right by k places, where k is non-negative.
Example 1: Input: 1->2->3->4->5->NULL, k = 2 Output: 4->5->1->2->3->NULL Explanation: rotate 1 steps to the right: 5->1->2->3->4->NULL rotate 2 steps to the right: 4->5->1->2->3->NULL
Example 2: Input: 0->1->2->NULL, k = 4 Output: 2->0->1->NULL Explanation: rotate 1 steps to the right: 2->0->1->NULL rotate 2 steps to the right: 1->2->0->NULL rotate 3 steps to the right: 0->1->2->NULL rotate 4 steps to the right: 2->0->1->NULL
高频
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution: defrotateRight(self, head: ListNode, k: int) -> ListNode: ifnot head: return head dummy = ListNode(0) dummy.next = head f = dummy l = 0 while f and f.next: f = f.next l += 1 s = dummy k %= l for _ inrange(l - k): s = s.next f.next = dummy.next dummy.next = s.next s.next = None return dummy.next
Design and implement a data structure for Least Recently Used (LRU) cache. It should support the following operations: get and put.
get(key) - Get the value (will always be positive) of the key if the key exists in the cache, otherwise return -1. put(key, value) - Set or insert the value if the key is not already present. When the cache reached its capacity, it should invalidate the least recently used item before inserting a new item. The cache is initialized with a positive capacity.
Follow up: Could you do both operations in O(1) time complexity?
Given a singly linked list, determine if it is a palindrome.
Example 1:
Input: 1->2 Output: false Example 2:
Input: 1->2->2->1 Output: true Follow up: Could you do it in O(n) time and O(1) space?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution: defisPalindrome(self, head: ListNode) -> bool: f = s = head pre_h = None while f and f.next: f = f.next.next next_h = s.next s.next = pre_h pre_h = s s = next_h if f: s = s.next while pre_h and pre_h.val == s.val: pre_h = pre_h.next s = s.next returnnot pre_h
3刷:高频, 慢指针边走边反转,当链表是奇数个时需要s跳过中间节点再s,pre_h同时前进:…if f: s = s.next…
Given a string containing just the characters '(', ')', '{', '}', '[' and ']', determine if the input string is valid.
An input string is valid if:
Open brackets must be closed by the same type of brackets. Open brackets must be closed in the correct order. Note that an empty string is also considered valid.
Example 1:
Input: "()" Output: true Example 2:
Input: "()[]{}" Output: true Example 3:
Input: "(]" Output: false Example 4:
Input: "([)]" Output: false Example 5:
Input: "{[]}" Output: true
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution: defisValid(self, s: str) -> bool: n = len(s) d = {')': '(', '}': '{', ']': '['} ll = '({[' stack = [] for c in s: if c in ll: stack.append(c) else: ifnot stack: returnFalse l = stack.pop(-1) if c notin d or l != d[c]: returnFalse returnlen(stack) == 0
Given an absolute path for a file (Unix-style), simplify it. Or in other words, convert it to the canonical path.
In a UNIX-style file system, a period . refers to the current directory. Furthermore, a double period .. moves the directory up a level. For more information, see: Absolute path vs relative path in Linux/Unix
Note that the returned canonical path must always begin with a slash /, and there must be only a single slash / between two directory names. The last directory name (if it exists) must not end with a trailing /. Also, the canonical path must be the shortest string representing the absolute path.
Example 1:
Input: "/home/" Output: "/home" Explanation: Note that there is no trailing slash after the last directory name. Example 2:
Input: "/../" Output: "/" Explanation: Going one level up from the root directory is a no-op, as the root level is the highest level you can go. Example 3:
Input: "/home//foo/" Output: "/home/foo" Explanation: In the canonical path, multiple consecutive slashes are replaced by a single one. Example 4:
Input: "/a/./b/../../c/" Output: "/c" Example 5:
Input: "/a/../../b/../c//.//" Output: "/c" Example 6:
Input: "/a//b////c/d//././/.." Output: "/a/b/c"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defsimplifyPath(self, path: str) -> str: t = path.split('/') s = [] for p in t: if p and p != '.': if p == '..': if s: s.pop() else: s.append(p) ifnot s: return'/' else: return'/' + '/'.join(s)
Evaluate the value of an arithmetic expression in Reverse Polish Notation.
Valid operators are +, -, *, /. Each operand may be an integer or another expression.
Note:
Division between two integers should truncate toward zero. The given RPN expression is always valid. That means the expression would always evaluate to a result and there won't be any divide by zero operation. Example 1:
classSolution: defevalRPN(self, tokens: List[str]) -> int: operators = "+-*/" s = [] for op in tokens: if op notin operators: s.append(int(op)) else: b = s.pop() a = s.pop() if op == "+": res = a + b elif op == "-": res = a - b elif op == '*': res = a * b elif op == "/": if a * b < 0and a % b != 0: res = a // b + 1 else: res = a // b s.append(res) return s[0]
Design a stack that supports push, pop, top, and retrieving the minimum element in constant time.
push(x) -- Push element x onto stack. pop() -- Removes the element on top of the stack. top() -- Get the top element. getMin() -- Retrieve the minimum element in the stack.
Implement a basic calculator to evaluate a simple expression string. The expression string may contain open ( and closing parentheses ), the plus + or minus sign -, non-negative integers and empty spaces .
Example 1: Input: “1 + 1” Output: 2 Example 2:
Input: “ 2-1 + 2 “ Output: 3 Example 3:
Input: “(1+(4+5+2)-3)+(6+8)” Output: 23 Note: You may assume that the given expression is always valid. Do not use the eval built-in library function.
classSolution: defcalculate(self, s: str) -> int: num, ans = 0, 0 sign = 1 stack = [] for c in s: if c.isdigit(): num = num * 10 + int(c) elif c in"+-": ans += sign * num num = 0 sign = 1if c == "+"else -1 elif c == "(": stack.append(ans) stack.append(sign) ans = 0 sign = 1 elif c == ")": ans += sign * num ans *= stack.pop() ans += stack.pop() num = 0 return ans + sign * num
Implement a basic calculator to evaluate a simple expression string. The expression string contains only non-negative integers, +, -, * , / operators and empty spaces . The integer division should truncate toward zero.
Example 1: Input: “3+2*2” Output: 7 Example 2:
Input: “ 3/2 “ Output: 1 Example 3:
Input: “ 3+5 / 2 “ Output: 5
Note: You may assume that the given expression is always valid. Do not use the eval built-in library function.
classSolution: defcalculate(self, s: str) -> int: stack = [] cur, pre_op = 0, ' ' for c in s + '+': if c in'+-*/': if pre_op in'*/': if pre_op == '*': cur *= stack[-1] if pre_op == '/': cur = int(stack[-1] / cur) stack.pop() if pre_op == '-': cur = -cur stack.append(cur) cur = 0 pre_op = c elif c != ' ': cur = cur * 10 + int(c) returnsum(stack)
classSolution: defcalculate(self, s: str) -> int: cur, pre_op, res, pre_v = 0, '+', 0, 0 for c in s + '+': if c in'+-*/': if pre_op == '*': pre_v *= cur if pre_op == '/': pre_v = int(pre_v / cur) if pre_op == '-': res += pre_v pre_v = -cur if pre_op == '+': res += pre_v pre_v = cur cur = 0 pre_op = c elif c != ' ': cur = cur * 10 + int(c) return res + pre_v
6刷: 面经:Cruise。难点: 1:preOp = …; …in s + ‘+’ 2. 给s加一个’+’尾巴处理最后一个运算符 3. -3 // 2 == -2 因为python是floor division返回less or equal to the closest integer比-1.5 less的integer是-2,所以要用int(../..)这样来除才能得到整数位的 4:O(n)空间的写法是要有一个preV的变量记录前一位的结果,如果前一个运算符是加减,则将preV加入res,最后返回res + preV
Given an array of integers temperatures represents the daily temperatures, return an array answer such that answer[i] is the number of days you have to wait after the ith day to get a warmer temperature. If there is no future day for which this is possible, keep answer[i] == 0 instead.
Example 1: Input: temperatures = [73,74,75,71,69,72,76,73] Output: [1,1,4,2,1,1,0,0]
Example 2: Input: temperatures = [30,40,50,60] Output: [1,1,1,0]
Example 3: Input: temperatures = [30,60,90] Output: [1,1,0]
classSolution: defdailyTemperatures(self, T: List[int]) -> List[int]: n = len(T) ans = [0] * n for i inrange(n): for j inrange(i + 1, n): if T[j] > T[i]: ans[i] = j - i break return ans
stack:
1 2 3 4 5 6 7 8 9 10 11 12
classSolution: defdailyTemperatures(self, temperatures: List[int]) -> List[int]: n = len(temperatures) ans = [0] * n stack = [n - 1] for i inrange(n - 2, -1, -1): while stack and temperatures[i] >= temperatures[stack[-1]]: stack.pop() if stack: ans[i] = stack[-1] - i stack.append(i) return anss
Given an encoded string, return its decoded string.
The encoding rule is: k[encoded_string], where the encoded_string inside the square brackets is being repeated exactly k times. Note that k is guaranteed to be a positive integer.
You may assume that the input string is always valid; No extra white spaces, square brackets are well-formed, etc.
Furthermore, you may assume that the original data does not contain any digits and that digits are only for those repeat numbers, k. For example, there won't be input like 3a or 2[4].
Example 1: Input: s = "3[a]2[bc]" Output: "aaabcbc"
Example 2: Input: s = "3[a2[c]]" Output: "accaccacc"
Example 3: Input: s = "2[abc]3[cd]ef" Output: "abcabccdcdcdef"
Example 4: Input: s = "abc3[cd]xyz" Output: "abccdcdcdxyz"
Constraints: 1 <= s.length <= 30 s consists of lowercase English letters, digits, and square brackets '[]'. s is guaranteed to be a valid input. All the integers in s are in the range [1, 300].
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution: defdecodeString(self, s: str) -> str: stack = [] ans = "" k = 0 for c in s: if c == "[": stack.append((ans, k)) ans = "" k = 0 elif c == "]": prev_w, prev_k = stack.pop() ans = prev_w + ans * prev_k elif c.isdigit(): k = k * 10 + int(c) else: ans += c return ans
写法2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution: defdecodeString(self, s: str) -> str: stack = [] for c in s: if c != ']': stack.append(c) else: w = deque() while stack[-1] != '[': w.appendleft(stack.pop()) stack.pop() k = deque() while stack and stack[-1].isdigit(): k.appendleft(stack.pop()) stack.append(''.join(w) * int(''.join(k))) return''.join(stack)
You are given a nested list of integers nestedList. Each element is either an integer or a list whose elements may also be integers or other lists. Implement an iterator to flatten it.
Implement the NestedIterator class:
NestedIterator(List<NestedInteger> nestedList) Initializes the iterator with the nested list nestedList. int next() Returns the next integer in the nested list. boolean hasNext() Returns true if there are still some integers in the nested list and false otherwise. Your code will be tested with the following pseudocode:
initialize iterator with nestedList res = [] while iterator.hasNext() append iterator.next() to the end of res return res If res matches the expected flattened list, then your code will be judged as correct.
Example 1: Input: nestedList = [[1,1],2,[1,1]] Output: [1,1,2,1,1] Explanation: By calling next repeatedly until hasNext returns false, the order of elements returned by next should be: [1,1,2,1,1].
Example 2: Input: nestedList = [1,[4,[6]]] Output: [1,4,6] Explanation: By calling next repeatedly until hasNext returns false, the order of elements returned by next should be: [1,4,6]. Constraints: 1 <= nestedList.length <= 500 The values of the integers in the nested list is in the range [-106, 106].
# """ # This is the interface that allows for creating nested lists. # You should not implement it, or speculate about its implementation # """ #class NestedInteger: # def isInteger(self) -> bool: # """ # @return True if this NestedInteger holds a single integer, rather than a nested list. # """ # # def getInteger(self) -> int: # """ # @return the single integer that this NestedInteger holds, if it holds a single integer # Return None if this NestedInteger holds a nested list # """ # # def getList(self) -> [NestedInteger]: # """ # @return the nested list that this NestedInteger holds, if it holds a nested list # Return None if this NestedInteger holds a single integer # """
classNestedIterator: def__init__(self, nestedList: [NestedInteger]): self.s = [[nestedList, 0]] defnext(self) -> int: l, i = self.s[-1] self.s[-1][1] += 1 return l[i].getInteger() defhasNext(self) -> bool: while self.s: l, i = self.s[-1] if i < len(l): if l[i].isInteger(): returnTrue else: self.s[-1][1] += 1 self.s.append([l[i].getList(), 0]) else: self.s.pop() returnFalse
# Your NestedIterator object will be instantiated and called as such: # i, v = NestedIterator(nestedList), [] # while i.hasNext(): v.append(i.next())
classSolution: defexclusiveTime(self, n: int, logs: List[str]) -> List[int]: stack = [] ans = [0] * n prev_t = 0 for log in logs: i, op, t = log.split(":") i, t = int(i), int(t) if op == "start": if stack: ans[stack[-1]] += t - prev_t stack.append(i) prev_t = t else: ans[stack.pop()] += t - prev_t + 1 prev_t = t + 1 return ans
Input: pattern = "abba", str = "dog dog dog dog" Output: false Notes: You may assume pattern contains only lowercase letters, and str contains lowercase letters separated by a single space.
Given a string which consists of lowercase or uppercase letters, find the length of the longest palindromes that can be built with those letters. This is case sensitive, for example “Aa” is not considered a palindrome here.
Note: Assume the length of given string will not exceed 1,010.
Example: Input: “abccccdd” Output: 7
Explanation: One longest palindrome that can be built is “dccaccd”, whose length is 7.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution(object): deflongestPalindrome(self, s): """ :type s: str :rtype: int """ ans = 0 from collections import Counter counter = Counter(s) for c, v in counter.items(): if v % 2 == 0or ans % 2 == 0: ans += v else: ans += v - 1 return ans
Design a data structure that supports all following operations in average O(1) time.
insert(val): Inserts an item val to the set if not already present. remove(val): Removes an item val from the set if present. getRandom: Returns a random element from current set of elements. Each element must have the same probability of being returned. Example:
// Init an empty set. RandomizedSet randomSet = new RandomizedSet();
// Inserts 1 to the set. Returns true as 1 was inserted successfully. randomSet.insert(1);
// Returns false as 2 does not exist in the set. randomSet.remove(2);
// Inserts 2 to the set, returns true. Set now contains [1,2]. randomSet.insert(2);
// getRandom should return either 1 or 2 randomly. randomSet.getRandom();
// Removes 1 from the set, returns true. Set now contains [2]. randomSet.remove(1);
// 2 was already in the set, so return false. randomSet.insert(2);
// Since 2 is the only number in the set, getRandom always return 2. randomSet.getRandom();
思路:看答案知道需要用 list 和 dictionary,因为要满足 O(1), 因为仅有 list 的 in 操作不能满足 O(1)
def__init__(self): """ Initialize your data structure here. """ self.list = [] self.dict = {}
definsert(self, val): """ Inserts a value to the set. Returns true if the set did not already contain the specified element. :type val: int :rtype: bool """ if val in self.dict: returnFalse else: self.list.append(val) self.dict[val] = len(self.list) - 1 returnTrue
defremove(self, val): """ Removes a value from the set. Returns true if the set contained the specified element. :type val: int :rtype: bool """ if val in self.dict: index, lastVal = self.dict[val], self.list[len(self.list) - 1] self.list[index], self.dict[lastVal] = lastVal, index self.list.pop() self.dict.pop(val) returnTrue else: returnFalse
defgetRandom(self): """ Get a random element from the set. :rtype: int """ return self.list[random.randint(0, len(self.list) - 1)]
# Your RandomizedSet object will be instantiated and called as such: # obj = RandomizedSet() # param_1 = obj.insert(val) # param_2 = obj.remove(val) # param_3 = obj.getRandom()
总结:可能是用 python 的原因,搞明白问什么了一次过
[LinC 960. First Unique Number in a Stream II (Medium)](960. First Unique Number in a Stream II)
1 2 3 4 5 6 7 8 9 10 11 12 13
Description We need to implement a data structure named DataStream. There are two methods required to be implemented:
void add(number) // add a new number int firstUnique() // return first unique number You can assume that there must be at least one unique number in the stream when calling the firstUnique.
Example add(1) add(2) firstUnique() => 1 add(1) firstUnique() => 2
def__init__(): # do intialization if necessary self.q = collections.deque() self.dict = {} """ @param num: next number in stream @return: nothing """ defadd(self, num): # write your code here if num in self.dict: self.dict[num] += 1 else: self.dict[num] = 1 self.q.append(num) """ @return: the first unique number in stream """ deffirstUnique(self): # write your code here whilelen(self.q) > 0and self.dict[self.q[0]] > 1: self.q.popleft() return self.q[0]
All inputs will be in lowercase. The order of your output does not matter.
高频
1 2 3 4 5 6 7
classSolution: defgroupAnagrams(self, strs: List[str]) -> List[List[str]]: d = collections.defaultdict(list) for s in strs: tmps = "".join(sorted(s)) d[tmps].append(s) return d.values()
In an alien language, surprisingly, they also use English lowercase letters, but possibly in a different order. The order of the alphabet is some permutation of lowercase letters.
Given a sequence of words written in the alien language, and the order of the alphabet, return true if and only if the given words are sorted lexicographically in this alien language.
Example 1: Input: words = ["hello","leetcode"], order = "hlabcdefgijkmnopqrstuvwxyz" Output: true Explanation: As 'h' comes before 'l' in this language, then the sequence is sorted.
Example 2: Input: words = ["word","world","row"], order = "worldabcefghijkmnpqstuvxyz" Output: false Explanation: As 'd' comes after 'l' in this language, then words[0] > words[1], hence the sequence is unsorted.
Example 3: Input: words = ["apple","app"], order = "abcdefghijklmnopqrstuvwxyz" Output: false Explanation: The first three characters "app" match, and the second string is shorter (in size.) According to lexicographical rules "apple" > "app", because 'l' > '∅', where '∅' is defined as the blank character which is less than any other character (More info).
Constraints: 1 <= words.length <= 100 1 <= words[i].length <= 20 order.length == 26 All characters in words[i] and order are English lowercase letters.
1 2 3 4 5 6 7 8 9 10 11 12
classSolution: defisAlienSorted(self, words: List[str], order: str) -> bool: d = {v:i for i, v inenumerate(order)} for w1, w2 inzip(words, words[1:]): for c1, c2 inzip(w1, w2): if d[c1] < d[c2]: break elif d[c1] > d[c2]: returnFalse if w1[:len(w2)] == w2 andlen(w1) > len(w2): returnFalse returnTrue
A linked list of length n is given such that each node contains an additional random pointer, which could point to any node in the list, or null.
Construct a deep copy of the list. The deep copy should consist of exactly n brand new nodes, where each new node has its value set to the value of its corresponding original node. Both the next and random pointer of the new nodes should point to new nodes in the copied list such that the pointers in the original list and copied list represent the same list state. None of the pointers in the new list should point to nodes in the original list.
For example, if there are two nodes X and Y in the original list, where X.random –> Y, then for the corresponding two nodes x and y in the copied list, x.random –> y.
Return the head of the copied linked list.
The linked list is represented in the input/output as a list of n nodes. Each node is represented as a pair of [val, random_index] where:
val: an integer representing Node.val random_index: the index of the node (range from 0 to n-1) that the random pointer points to, or null if it does not point to any node. Your code will only be given the head of the original linked list.
Example 1: Input: head = [[7,null],[13,0],[11,4],[10,2],[1,0]] Output: [[7,null],[13,0],[11,4],[10,2],[1,0]]
Example 2: Input: head = [[1,1],[2,1]] Output: [[1,1],[2,1]]
Example 3: Input: head = [[3,null],[3,0],[3,null]] Output: [[3,null],[3,0],[3,null]]
Example 4: Input: head = [] Output: [] Explanation: The given linked list is empty (null pointer), so return null.
Constraints: 0 <= n <= 1000 -10000 <= Node.val <= 10000 Node.random is null or is pointing to some node in the linked list.
1 2 3 4 5 6 7 8 9 10 11
classSolution: defcopyRandomList(self, head: 'Node') -> 'Node': d = defaultdict(lambda: Node(0)) d[None] = None p = head while p: d[p].val = p.val d[p].next = d[p.next] d[p].random = d[p.random] p = p.next return d[head]
We have a list of points on the plane. Find the K closest points to the origin (0, 0). (Here, the distance between two points on a plane is the Euclidean distance.) You may return the answer in any order. The answer is guaranteed to be unique (except for the order that it is in.)
Example 1: Input: points = [[1,3],[-2,2]], K = 1 Output: [[-2,2]] Explanation: The distance between (1, 3) and the origin is sqrt(10). The distance between (-2, 2) and the origin is sqrt(8). Since sqrt(8) < sqrt(10), (-2, 2) is closer to the origin. We only want the closest K = 1 points from the origin, so the answer is just [[-2,2]].
Example 2: Input: points = [[3,3],[5,-1],[-2,4]], K = 2 Output: [[3,3],[-2,4]] (The answer [[-2,4],[3,3]] would also be accepted.)
classSolution: defkClosest(self, points: List[List[int]], k: int) -> List[List[int]]: pq = [] for [x, y] in points: iflen(pq) < k: heapq.heappush(pq, (- x * x - y * y, x, y)) else: heapq.heappushpop(pq, (- x * x - y * y, x, y)) return [[x, y] for v, x, y in pq]
Implement a data structure, provide two interfaces: add(number). Add a new number in the data structure. topk(). Return the top k largest numbers in this data structure. k is given when we create the data structure.
Example s = new Solution(3); >> create a new data structure. s.add(3) s.add(10) s.topk() >> return [10, 3] s.add(1000) s.add(-99) s.topk() >> return [1000, 10, 3] s.add(4) s.topk() >> return [1000, 10, 4] s.add(100) s.topk() >> return [1000, 100, 10]
classSolution: """ @param: k: An integer """ def__init__(self, k): # do intialization if necessary self.k = k self.q = [] """ @param: num: Number to be added @return: nothing """ defadd(self, num): # write your code here import heapq heapq.heappush(self.q, num) iflen(self.q) > self.k: heapq.heappop(self.q) """ @return: Top k element """ deftopk(self): # write your code here returnsorted(self.q, reverse = True)
总结:一句 sorted(self.q, reverse = True) 完爆。。。哎, python 的 buit-in function 返回一个 sorted new list…学习了。
classSolution: defmergeKLists(self, lists: List[ListNode]) -> ListNode: dummy = cur = ListNode(0) h = [] import heapq for i, n inenumerate(lists): if n: heapq.heappush(h, (n.val, i, n)) while h: v, i, n = heapq.heappop(h) cur.next = n cur = cur.next if n.next: heapq.heappush(h, (n.next.val, i, n.next)) return dummy.next
classSolution: defmergeKLists(self, lists: List[ListNode]) -> ListNode: ifnot lists: returnNone n = len(lists) if n == 1: return lists[0] mid = n // 2 l = self.mergeKLists(lists[:mid]) r = self.mergeKLists(lists[mid:]) defmerge(l, r): dummy = cur = ListNode(0) while l and r: if l.val < r.val: cur.next = l l = l.next else: cur.next = r r = r.next cur = cur.next cur.next = l ifnot r else r return dummy.next return merge(l, r)
三种方法,都需要练习. 方法一:使用 PriorityQueue 方法二:类似归并排序的分治算法 方法三:自底向上的两两归并算法. 时间复杂度均为 O(NlogK) Strong Hire: 能够用至少2种方法进行实现,代码无大 BUG 高频:如果不能加lt(),就用(n.val, i, n)tuple防v.val重复的。 todo 把缺的第三种方法补了
Median is the middle value in an ordered integer list. If the size of the list is even, there is no middle value. So the median is the mean of the two middle value.
For example, [2,3,4], the median is 3 [2,3], the median is (2 + 3) / 2 = 2.5
Design a data structure that supports the following two operations: void addNum(int num) - Add a integer number from the data stream to the data structure. double findMedian() - Return the median of all elements so far.
Follow up: If all integer numbers from the stream are between 0 and 100, how would you optimize it? If 99% of all integer numbers from the stream are between 0 and 100, how would you optimize it?
There are N network nodes, labelled 1 to N. Given times, a list of travel times as directed edges times[i] = (u, v, w), where u is the source node, v is the target node, and w is the time it takes for a signal to travel from source to target. Now, we send a signal from a certain node K. How long will it take for all nodes to receive the signal? If it is impossible, return -1. Example 1: Input: times = [[2,1,1],[2,3,1],[3,4,1]], N = 4, K = 2 Output: 2 Note: N will be in the range [1, 100]. K will be in the range [1, N]. The length of times will be in the range [1, 6000]. All edges times[i] = (u, v, w) will have 1 <= u, v <= N and 0 <= w <= 100.
classSolution: defnetworkDelayTime(self, times: List[List[int]], N: int, K: int) -> int: graph = collections.defaultdict(dict) for u, v, w in times: graph[u - 1][v - 1] = w distances = [sys.maxsize] * N distances[K - 1] = 0 pq = [(0, K - 1)] seen = set() while pq: dist, v1 = heapq.heappop(pq) if v1 notin seen: seen.add(v1) for v2 in graph[v1]: if v2 notin seen: prev = distances[v2] cur = dist + graph[v1][v2] if cur < prev: distances[v2] = cur heapq.heappush(pq, (cur, v2)) ans = max(distances) return -1if ans == sys.maxsize else ans
There are n cities connected by m flights. Each fight starts from city u and arrives at v with a price w.
Now given all the cities and flights, together with starting city src and the destination dst, your task is to find the cheapest price from src to dst with up to k stops. If there is no such route, output -1.
Example 1: Input: n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]] src = 0, dst = 2, k = 1 Output: 200 Explanation: The graph looks like this:
The cheapest price from city 0 to city 2 with at most 1 stop costs 200, as marked red in the picture. Example 2: Input: n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]] src = 0, dst = 2, k = 0 Output: 500 Explanation: The graph looks like this:
The cheapest price from city 0 to city 2 with at most 0 stop costs 500, as marked blue in the picture. Note:
The number of nodes n will be in range [1, 100], with nodes labeled from 0 to n - 1. The size of flights will be in range [0, n * (n - 1) / 2]. The format of each flight will be (src, dst, price). The price of each flight will be in the range [1, 10000]. k is in the range of [0, n - 1]. There will not be any duplicated flights or self cycles.
In an exam room, there are N seats in a single row, numbered 0, 1, 2, …, N-1. When a student enters the room, they must sit in the seat that maximizes the distance to the closest person. If there are multiple such seats, they sit in the seat with the lowest number. (Also, if no one is in the room, then the student sits at seat number 0.) Return a class ExamRoom(int N) that exposes two functions: ExamRoom.seat() returning an int representing what seat the student sat in, and ExamRoom.leave(int p) representing that the student in seat number p now leaves the room. It is guaranteed that any calls to ExamRoom.leave(p) have a student sitting in seat p.
Example 1: Input: [“ExamRoom”,”seat”,”seat”,”seat”,”seat”,”leave”,”seat”], [[10],[],[],[],[],[4],[]] Output: [null,0,9,4,2,null,5] Explanation: ExamRoom(10) -> null seat() -> 0, no one is in the room, then the student sits at seat number 0. seat() -> 9, the student sits at the last seat number 9. seat() -> 4, the student sits at the last seat number 4. seat() -> 2, the student sits at the last seat number 2. leave(4) -> null seat() -> 5, the student sits at the last seat number 5.
Note: 1 <= N <= 10^9 ExamRoom.seat() and ExamRoom.leave() will be called at most 10^4 times across all test cases. Calls to ExamRoom.leave(p) are guaranteed to have a student currently sitting in seat number p.
Design a data structure that supports the following two operations:
void addWord(word) bool search(word) search(word) can search a literal word or a regular expression string containing only letters a-z or .. A . means it can represent any one letter.
Example:
addWord(“bad”) addWord(“dad”) addWord(“mad”) search(“pad”) -> false search(“bad”) -> true search(“.ad”) -> true search(“b..”) -> true Note: You may assume that all words are consist of lowercase letters a-z.
defaddWord(self, word: str) -> None: root = self.root for c in word: root = root.children[c] root.eow = True
defsearch(self, word: str) -> bool: deffind(root, word): iflen(word) == 0: return root.eow else: c = word[0] if c == '.': returnany([find(child, word[1:]) for child in root.children.values()]) else: return find(root.children[c], word[1:]) if c in root.children elseFalse return find(self.root, word)
Given a list of Connections, which is the Connection class (the city name at both ends of the edge and a cost between them), find edges that can connect all the cities and spend the least amount. Return the connects if can connect all the cities, otherwise return empty list.
Example Example 1:
Input: [“Acity”,”Bcity”,1] [“Acity”,”Ccity”,2] [“Bcity”,”Ccity”,3] Output: [“Acity”,”Bcity”,1] [“Acity”,”Ccity”,2] Example 2:
Explanation: No way Notice Return the connections sorted by the cost, or sorted city1 name if their cost is same, or sorted city2 if their city1 name is also same.
''' Definition for a Connection class Connection: def __init__(self, city1, city2, cost): self.city1, self.city2, self.cost = city1, city2, cost ''' classUnion: def__init__(self, n): self.size = n self.graph = {} for i inrange(n): self.graph[i] = i
classSolution: # @param {Connection[]} connections given a list of connections # include two cities and cost # @return {Connection[]} a list of connections from results deflowestCost(self, connections): # Write your code here connections.sort(key = lambda x: x.city2) connections.sort(key = lambda x: x.city1) connections.sort(key = lambda x: x.cost) citymap = {} cnt = 0 ans = [] for c in connections: if c.city1 notin citymap: citymap[c.city1] = cnt cnt += 1 if c.city2 notin citymap: citymap[c.city2] = cnt cnt += 1 union = Union(cnt) for c in connections: c1 = citymap[c.city1] c2 = citymap[c.city2]
ifnot union.query(c1, c2): union.connect(c1, c2) ans.append(c) return ans if union.all_connected() else []
Given a list of accounts where each element accounts[i] is a list of strings, where the first element accounts[i][0] is a name, and the rest of the elements are emails representing emails of the account.
Now, we would like to merge these accounts. Two accounts definitely belong to the same person if there is some common email to both accounts. Note that even if two accounts have the same name, they may belong to different people as people could have the same name. A person can have any number of accounts initially, but all of their accounts definitely have the same name.
After merging the accounts, return the accounts in the following format: the first element of each account is the name, and the rest of the elements are emails in sorted order. The accounts themselves can be returned in any order.
classSolution: defaccountsMerge(self, accounts: List[List[str]]) -> List[List[str]]: d = defaultdict(list) for i, a inenumerate(accounts): for e in a[1:]: d[e].append(i) defdfs(i): seen[i] = True for e in accounts[i][1:]: cur.add(e) for neighbor in d[e]: ifnot seen[neighbor]: dfs(neighbor) n = len(accounts) ans = [] seen = [False] * n for i inrange(n): ifnot seen[i]: cur = set() dfs(i) ans.append([accounts[i][0]] + sorted(cur)) return ans
classSolution: defaccountsMerge(self, accounts: List[List[str]]) -> List[List[str]]: deffind(i): if parent[i] != i: return find(parent[i]) return i defunion(x, y): px, py = find(x), find(y) parent[px] = py n = len(accounts) parent = list(range(n)) e_2_i = defaultdict(list) for i, a inenumerate(accounts): for e in a[1:]: e_2_i[e].append(i) for ids in e_2_i.values(): for i in ids[1:]: union(ids[0], i) res = defaultdict(set) for i, a inenumerate(accounts): res[find(i)].update(a[1:]) return [[accounts[k][0]] + sorted(v) for k, v in res.items()]
Say you have an array for which the ith element is the price of a given stock on day i. If you were only permitted to complete at most one transaction (i.e., buy one and sell one share of the stock), design an algorithm to find the maximum profit. Note that you cannot sell a stock before you buy one.
Example 1: Input: [7,1,5,3,6,4] Output: 5 Explanation: Buy on day 2 (price = 1) and sell on day 5 (price = 6), profit = 6-1 = 5. Not 7-1 = 6, as selling price needs to be larger than buying price.
Example 2: Input: [7,6,4,3,1] Output: 0 Explanation: In this case, no transaction is done, i.e. max profit = 0.
classSolution: defmaxProfit(self, prices: List[int]) -> int: low = prices[0] ans = 0 for p in prices[1:]: ans = max(ans, p - low) low = min(low, p) return ans
Say you have an array for which the ith element is the price of a given stock on day i. Design an algorithm to find the maximum profit. You may complete as many transactions as you like (i.e., buy one and sell one share of the stock multiple times). Note: You may not engage in multiple transactions at the same time (i.e., you must sell the stock before you buy again).
Example 1: Input: [7,1,5,3,6,4] Output: 7 Explanation: Buy on day 2 (price = 1) and sell on day 3 (price = 5), profit = 5-1 = 4. Then buy on day 4 (price = 3) and sell on day 5 (price = 6), profit = 6-3 = 3.
Example 2: Input: [1,2,3,4,5] Output: 4 Explanation: Buy on day 1 (price = 1) and sell on day 5 (price = 5), profit = 5-1 = 4. Note that you cannot buy on day 1, buy on day 2 and sell them later, as you are engaging multiple transactions at the same time. You must sell before buying again. Example 3: Input: [7,6,4,3,1] Output: 0 Explanation: In this case, no transaction is done, i.e. max profit = 0.
1 2 3 4 5 6 7 8 9 10
classSolution: defmaxProfit(self, prices: List[int]) -> int: n = len(prices) f = [0] * n for i inrange(1, n): if prices[i] <= prices[i - 1]: f[i] = f[i - 1] else: f[i] = max(f[i], f[i - 1] + prices[i] - prices[i - 1]) return f[-1]
A robot is located at the top-left corner of a m x n grid (marked 'Start' in the diagram below).
The robot can only move either down or right at any point in time. The robot is trying to reach the bottom-right corner of the grid (marked 'Finish' in the diagram below).
How many possible unique paths are there?
Above is a 7 x 3 grid. How many possible unique paths are there?
Note: m and n will be at most 100.
Example 1:
Input: m = 3, n = 2 Output: 3 Explanation: From the top-left corner, there are a total of 3 ways to reach the bottom-right corner: 1. Right -> Right -> Down 2. Right -> Down -> Right 3. Down -> Right -> Right Example 2:
Input: m = 7, n = 3 Output: 28
1 2 3 4 5 6 7 8 9
classSolution: defuniquePaths(self, m: int, n: int) -> int: if m == 1or n == 1: return1 f = [[1for _ inrange(m + 1)] for _ inrange(n + 1)] for r inrange(2, n + 1): for c inrange(2, m + 1): f[r][c] = f[r - 1][c] + f[r][c - 1] return f[n][m]
A robot is located at the top-left corner of a m x n grid (marked ‘Start’ in the diagram below). The robot can only move either down or right at any point in time. The robot is trying to reach the bottom-right corner of the grid (marked ‘Finish’ in the diagram below). Now consider if some obstacles are added to the grids. How many unique paths would there be? An obstacle and empty space is marked as 1 and 0 respectively in the grid. Note: m and n will be at most 100.
Example 1: Input: [ [0,0,0], [0,1,0], [0,0,0] ] Output: 2 Explanation: There is one obstacle in the middle of the 3x3 grid above. There are two ways to reach the bottom-right corner:
Right -> Right -> Down -> Down
Down -> Down -> Right -> Right
space O(mxn):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defuniquePathsWithObstacles(self, obstacleGrid: List[List[int]]) -> int: if obstacleGrid[0][0] == 1: return0 m, n = len(obstacleGrid), len(obstacleGrid[0]) f = [[0] * n for _ inrange(m)] f[0][0] = 1 for c inrange(1, n): f[0][c] = 0if obstacleGrid[0][c] == 1else f[0][c - 1] for r inrange(1, m): f[r][0] = 0if obstacleGrid[r][0] == 1else f[r - 1][0] for r inrange(1, m): for c inrange(1, n): f[r][c] = 0if obstacleGrid[r][c] == 1else f[r - 1][c] + f[r][c - 1] return f[-1][-1]
space: O(n):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defuniquePathsWithObstacles(self, obstacleGrid: List[List[int]]) -> int: if obstacleGrid[0][0] == 1: return0 m, n = len(obstacleGrid), len(obstacleGrid[0]) f = [0] * n f[0] = 1 for c inrange(1, n): f[c] = 0if obstacleGrid[0][c] == 1else f[c - 1] for r inrange(1, m): if obstacleGrid[r][0] == 1: f[0] = 0 for c inrange(1, n): f[c] = 0if obstacleGrid[r][c] == 1else f[c] + f[c - 1] return f[-1]
Given a m x n grid filled with non-negative numbers, find a path from top left to bottom right which minimizes the sum of all numbers along its path.
Note: You can only move either down or right at any point in time.
Example:
Input: [ [1,3,1], [1,5,1], [4,2,1] ] Output: 7 Explanation: Because the path 1→3→1→1→1 minimizes the sum. 空间O(m*n):
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: defminPathSum(self, grid: List[List[int]]) -> int: m, n = len(grid), len(grid[0]) f = [[0] * n for _ inrange(m)] f[0][0] = grid[0][0] for c inrange(1, n): f[0][c] = f[0][c - 1] + grid[0][c] for r inrange(1, m): f[r][0] = f[r - 1][0] + grid[r][0] for r inrange(1, m): for c inrange(1, n): f[r][c] = min(f[r - 1][c], f[r][c - 1]) + grid[r][c] return f[-1][-1]
空间O(n):
1 2 3 4 5 6 7 8 9 10 11 12
classSolution: defminPathSum(self, grid: List[List[int]]) -> int: m, n = len(grid), len(grid[0]) f = [0] * n f[0] = grid[0][0] for c inrange(1, n): f[c] = f[c - 1] + grid[0][c] for r inrange(1, m): f[0] += grid[r][0] for c inrange(1, n): f[c] = min(f[c], f[c - 1]) + grid[r][c] return f[-1]
Given a string s, find the longest palindromic substring in s. You may assume that the maximum length of s is 1000.
Example 1:
Input: "babad" Output: "bab" Note: "aba" is also a valid answer. Example 2:
Input: "cbbd" Output: "bb"
Expand around center:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution: deflongestPalindrome(self, s: str) -> str: defaroundI(l, r): while l >= 0and r < n and s[l] == s[r]: l -= 1 r += 1 return l + 1, r - 1 n = len(s) ans = (0, 0) for i inrange(n): l, r = aroundI(i, i) if r - l > ans[1] - ans[0]: ans = (l, r) l, r = aroundI(i, i + 1) if r - l > ans[1] - ans[0]: ans = (l, r) return s[ans[0]:ans[1] + 1]
dp:
1 2 3 4 5 6 7 8 9 10 11 12
classSolution: deflongestPalindrome(self, s: str) -> str: n = len(s) f = [[False] * n for _ inrange(n)] ans = (0, 0) for l inrange(n - 1, -1 , -1): for r inrange(l, n): if s[l] == s[r] and (r - l <= 2or f[l + 1][r - 1]): f[l][r] = True if r - l > ans[1] - ans[0]: ans = (l, r) return s[ans[0]:ans[1] + 1]
暴力 TLE:
1 2 3 4 5 6 7 8 9
classSolution: deflongestPalindrome(self, s: str) -> str: n = len(s) ans = '' for i inrange(n): for j inrange(i + 1, n + 1): if s[i:j] == s[i:j][::-1] and j - i > len(ans): ans = s[i:j] return ans
4刷:高频:expand around center…def aroundI(l, r):…return l + 1, r…。dp: f为从i到j是否为回文串,…for j in range(n): for i in range(j + 1):…
Given an array of non-negative integers, you are initially positioned at the first index of the array.
Each element in the array represents your maximum jump length at that position.
Determine if you are able to reach the last index.
Example 1:
Input: [2,3,1,1,4] Output: true Explanation: Jump 1 step from index 0 to 1, then 3 steps to the last index. Example 2:
Input: [3,2,1,0,4] Output: false Explanation: You will always arrive at index 3 no matter what. Its maximum jump length is 0, which makes it impossible to reach the last index.
dp:
1 2 3 4 5 6 7 8 9
classSolution: defcanJump(self, nums: List[int]) -> bool: f = [0for _ inrange(len(nums))] f[0] = nums[0] for i inrange(1, len(nums)): f[i] = max(f[i - 1], nums[i - 1]) - 1 if f[i] < 0: returnFalse returnTrue
greedy:
1 2 3 4 5 6 7 8
classSolution: defcanJump(self, nums: List[int]) -> bool: reach = 0 for i, n inenumerate(nums): if i > reach: returnFalse reach = max(reach, i + n) returnTrue
Given an integer n, generate all structurally unique BST's (binary search trees) that store values 1 ... n.
Example:
Input: 3 Output: [ [1,null,3,2], [3,2,null,1], [3,1,null,null,2], [2,1,3], [1,null,2,null,3] ] Explanation: The above output corresponds to the 5 unique BST's shown below:
1 3 3 2 1 \ / / / \ \ 3 2 1 1 3 2 / / \ \ 2 1 2 3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution: defgenerateTrees(self, n: int) -> List[TreeNode]: if n == 0: return [] defgen(s, e): if s > e: return [None] res = [] for i inrange(s, e + 1): for l in gen(s, i - 1): for r in gen(i + 1, e): root = TreeNode(i) root.left = l root.right = r res.append(root) return res return gen(1, n)
高频:看着像非主流dp题。…def gen(s, e):…res = []…for l in gen(s, i - 1):…return gen(1, n)
You are a professional robber planning to rob houses along a street. Each house has a certain amount of money stashed, the only constraint stopping you from robbing each of them is that adjacent houses have security system connected and it will automatically contact the police if two adjacent houses were broken into on the same night.
Given a list of non-negative integers representing the amount of money of each house, determine the maximum amount of money you can rob tonight without alerting the police.
Example 1:
Input: [1,2,3,1] Output: 4 Explanation: Rob house 1 (money = 1) and then rob house 3 (money = 3). Total amount you can rob = 1 + 3 = 4. Example 2:
Input: [2,7,9,3,1] Output: 12 Explanation: Rob house 1 (money = 2), rob house 3 (money = 9) and rob house 5 (money = 1). Total amount you can rob = 2 + 9 + 1 = 12.
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: defrob(self, nums: List[int]) -> int: n = len(nums) if n == 0: return0 if n == 1: return nums[0] f = [0] * n f[0] = nums[0] f[1] = max(nums[0], nums[1]) for i inrange(2, n): f[i] = max(f[i - 2] + nums[i], f[i - 1]) return f[n - 1]
You are a professional robber planning to rob houses along a street. Each house has a certain amount of money stashed. All houses at this place are arranged in a circle. That means the first house is the neighbor of the last one. Meanwhile, adjacent houses have security system connected and it will automatically contact the police if two adjacent houses were broken into on the same night. Given a list of non-negative integers representing the amount of money of each house, determine the maximum amount of money you can rob tonight without alerting the police.
Example 1: Input: [2,3,2] Output: 3 Explanation: You cannot rob house 1 (money = 2) and then rob house 3 (money = 2), because they are adjacent houses. Example 2: Input: [1,2,3,1] Output: 4 Explanation: Rob house 1 (money = 1) and then rob house 3 (money = 3). Total amount you can rob = 1 + 3 = 4.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution: defrob(self, nums: List[int]) -> int: n = len(nums) if n == 0: return0 if n == 1: return nums[0] if n == 2: returnmax(nums[0], nums[1]) dp1 = [0] * n dp2 = [0] * n dp1[0] = nums[0] dp2[0] = 0 dp1[1] = dp1[0] dp2[1] = nums[1] for i inrange(2, n - 1): dp1[i] = max(dp1[i - 1], dp1[i - 2] + nums[i]) dp2[i] = max(dp2[i - 1], dp2[i - 2] + nums[i]) returnmax(dp1[n - 2], max(dp2[n - 2], dp2[n - 3] + nums[n - 1]))
Given an input string (s) and a pattern (p), implement regular expression matching with support for '.' and '*'.
'.' Matches any single character. '*' Matches zero or more of the preceding element. The matching should cover the entire input string (not partial).
Note:
s could be empty and contains only lowercase letters a-z. p could be empty and contains only lowercase letters a-z, and characters like . or *. Example 1:
Input: s = "aa" p = "a" Output: false Explanation: "a" does not match the entire string "aa". Example 2:
Input: s = "aa" p = "a*" Output: true Explanation: '*' means zero or more of the precedeng element, 'a'. Therefore, by repeating 'a' once, it becomes "aa". Example 3:
Input: s = "ab" p = ".*" Output: true Explanation: ".*" means "zero or more (*) of any character (.)". Example 4:
Input: s = "aab" p = "c*a*b" Output: true Explanation: c can be repeated 0 times, a can be repeated 1 time. Therefore it matches "aab". Example 5:
Input: s = "mississippi" p = "mis*is*p*." Output: false
DP:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution: defisMatch(self, s: str, p: str) -> bool: ls, lp = len(s), len(p) f = [[False] * (lp + 1) for _ inrange(ls + 1)] f[0][0] = True for j inrange(1, lp): if p[j] == '*': f[0][j + 1] = f[0][j - 1] for i inrange(ls): for j inrange(lp): if p[j] == '.'or s[i] == p[j]: f[i + 1][j + 1] = f[i][j] if p[j] == '*': if s[i] != p[j - 1] and p[j - 1] != '.': f[i + 1][j + 1] = f[i + 1][j - 1] else: f[i + 1][j + 1] = f[i][j + 1] or f[i + 1][j] or f[i + 1][j - 1] return f[-1][-1]
Backtracking:
1 2 3 4 5 6 7 8 9
classSolution: defisMatch(self, s: str, p: str) -> bool: ifnot p: returnnot s first_matched = len(s) > 0and (s[0] == p[0] or p[0] == '.') iflen(p) > 1and p[1] == '*': return self.isMatch(s, p[2:]) or (first_matched and self.isMatch(s[1:], p)) else: return first_matched and self.isMatch(s[1:], p[1:])
高频:dp:怎么写都不是很直观,目前采用range和p[],s[]取值简化写。当前p的字符位’.’或者和s当前字符相等即前进。’*‘分两种情况:1.p前一位不是’.’与当前s字符也不等,a* counts as empty 2.等或者是’.(*)’,a* counts as multiple a / a* counts as single a / a* counts as empty。时间空间复杂度均为O(lslp) backtracking: 关键要用s = “aab” p = “cab”来记住如果有,要么忽略这部分p,要么删掉第一个匹配的字符这个算法。…if not p:…firt_matched = len(s) > 0 and (s[0]…)…时间空间复杂度:leetcode solution里有,较复杂
Given an input string (s) and a pattern (p), implement wildcard pattern matching with support for ‘?’ and ‘‘. ‘?’ Matches any single character. ‘‘ Matches any sequence of characters (including the empty sequence). The matching should cover the entire input string (not partial).
Note: s could be empty and contains only lowercase letters a-z. p could be empty and contains only lowercase letters a-z, and characters like ? or * .
Example 1: Input: s = “aa” p = “a” Output: false Explanation: “a” does not match the entire string “aa”.
Example 2: Input: s = “aa” p = ““ Output: true Explanation: ‘‘ matches any sequence.
Example 3: Input: s = “cb” p = “?a” Output: false Explanation: ‘?’ matches ‘c’, but the second letter is ‘a’, which does not match ‘b’.
Example 4: Input: s = “adceb” p = “ab” Output: true Explanation: The first ‘‘ matches the empty sequence, while the second ‘ ‘ matches the substring “dce”.
Example 5: Input: s = “acdcb” p = “a*c?b” Output: false
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defisMatch(self, s: str, p: str) -> bool: ls, lp = len(s), len(p) dp = [[False] * (lp + 1) for _ inrange(ls + 1)] dp[0][0] = True for j inrange(lp): if p[j] == '*': dp[0][j + 1] = dp[0][j] for i inrange(ls): for j inrange(lp): if s[i] == p[j] or p[j] == '?': dp[i + 1][j + 1] = dp[i][j] elif p[j] == '*': dp[i + 1][j + 1] = dp[i][j + 1] or dp[i + 1][j] return dp[-1][-1]
高频:和上题统一的模板,当j位置的p是’?’ 或者和i位置���s相等时,均前进…f[i + 1][j + 1] = f[i][j],当j位置是’*‘时,两种情况,* count as multiple char / * count as single char …f[i + 1][j + 1] = f[i][j + 1] or f[i + 1][j]… 面经:Quora。
Given a non-empty string s and a dictionary wordDict containing a list of non-empty words, determine if s can be segmented into a space-separated sequence of one or more dictionary words.
Note: The same word in the dictionary may be reused multiple times in the segmentation. You may assume the dictionary does not contain duplicate words.
Example 1: Input: s = “leetcode”, wordDict = [“leet”, “code”] Output: true Explanation: Return true because “leetcode” can be segmented as “leet code”.
Example 2: Input: s = “applepenapple”, wordDict = [“apple”, “pen”] Output: true Explanation: Return true because “applepenapple” can be segmented as “apple pen apple”. Note that you are allowed to reuse a dictionary word. Example 3: Input: s = “catsandog”, wordDict = [“cats”, “dog”, “sand”, “and”, “cat”] Output: false
1 2 3 4 5 6 7 8 9 10
classSolution: defwordBreak(self, s: str, wordDict: List[str]) -> bool: n = len(s) f = [False] * (n + 1) f[0] = True for i inrange(n): for j inrange(i + 1, n + 1): if s[i:j] in wordDict and f[i]: f[j] = True return f[-1]
Note that different sequences are counted as different combinations. Therefore the output is 7.
Follow up: What if negative numbers are allowed in the given array? How does it change the problem? What limitation we need to add to the question to allow negative numbers? memo[4] = memo[4 - 1] + memo[4 - 3] + memo[4 - 1]的方法:
classSolution: defcombinationSum4(self, nums: List[int], target: int) -> int: return self.dfs(nums, target, {}) defdfs(self, nums, target, memo): if target == 0: return1 if target in memo: return memo[target] res = 0 for i inrange(len(nums)): if target >= nums[i]: res += self.dfs(nums, target - nums[i], memo) memo[target] = res return res
Given a string s, find the longest palindromic subsequence’s length in s. You may assume that the maximum length of s is 1000.
Example 1: Input: “bbbab” Output: 4 One possible longest palindromic subsequence is “bbbb”.
Example 2: Input: “cbbd” Output: 2 One possible longest palindromic subsequence is “bb”.
brute force recursion O(2^n) worst case TLE:
1 2 3 4 5 6 7 8 9
classSolution: deflongestPalindromeSubseq(self, s: str) -> int: return self.helper(0, len(s) - 1, s) defhelper(self, l, r, s): if l == r: return1 if l > r: return0 return2 + self.helper(l + 1, r - 1, s) if s[l] == s[r] elsemax(self.helper(l + 1, r, s), self.helper(l, r - 1, s))
add memo time complexity to O(n^2):
1 2 3 4 5 6 7 8 9 10 11 12
classSolution: deflongestPalindromeSubseq(self, s: str) -> int: return self.helper(0, len(s) - 1, s, {}) defhelper(self, l, r, s, memo): if l == r: return1 if l > r: return0 if (l, r) in memo: return memo[(l, r)] memo[(l, r)] = 2 + self.helper(l + 1, r - 1, s, memo) if s[l] == s[r] elsemax(self.helper(l + 1, r, s, memo), self.helper(l, r - 1, s, memo)) return memo[(l, r)]
dp:
1 2 3 4 5 6 7 8 9 10 11 12
classSolution: deflongestPalindromeSubseq(self, s: str) -> int: n = len(s) dp = [[0] * n for _ inrange(n)] for i inrange(n - 1, -1, -1): dp[i][i] = 1 for j inrange(i + 1, n): if s[i] == s[j]: dp[i][j] = dp[i + 1][j - 1] + 2 else: dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]) return dp[0][-1]
面经:维萨 Subsequence is not substring. Every sub string is a sub sequence e.g. leetcode Both substring and subsequence leet, code Sub sequence ltcode, eecode, ecode, ltde // and not substring dp:从 i 到 j, dp[i][i] = 1, i从最后一个开始,j从i+1开始,构建斜上半个dpmatrix, 如果s[i] == s[j]: dp[i][j] = dp[i + 1][j - 1] + 2 else: dp[i][j] = max(dp[i + 1][j], dp[i][j - 1])
Given an unsorted array of integers, find the length of longest increasing subsequence.
Example: Input: [10,9,2,5,3,7,101,18] Output: 4 Explanation: The longest increasing subsequence is [2,3,7,101], therefore the length is 4. Note:
There may be more than one LIS combination, it is only necessary for you to return the length. Your algorithm should run in O(n2) complexity. Follow up: Could you improve it to O(n log n) time complexity?
DP: O(n^2):
1 2 3 4 5 6 7 8 9
classSolution: deflengthOfLIS(self, nums: List[int]) -> int: n = len(nums) f = [1] * n for i inrange(n): for j inrange(i): if nums[i] > nums[j] and f[i] < f[j] + 1: f[i] = f[j] + 1 returnmax(f)
Given two strings text1 and text2, return the length of their longest common subsequence. A subsequence of a string is a new string generated from the original string with some characters(can be none) deleted without changing the relative order of the remaining characters. (eg, “ace” is a subsequence of “abcde” while “aec” is not). A common subsequence of two strings is a subsequence that is common to both strings. If there is no common subsequence, return 0.
Example 1: Input: text1 = “abcde”, text2 = “ace” Output: 3 Explanation: The longest common subsequence is “ace” and its length is 3.
Example 2: Input: text1 = “abc”, text2 = “abc” Output: 3 Explanation: The longest common subsequence is “abc” and its length is 3.
Example 3: Input: text1 = “abc”, text2 = “def” Output: 0 Explanation: There is no such common subsequence, so the result is 0.
Constraints: 1 <= text1.length <= 1000 1 <= text2.length <= 1000 The input strings consist of lowercase English characters only.
1 2 3 4 5 6 7 8 9 10 11
classSolution: deflongestCommonSubsequence(self, text1: str, text2: str) -> int: m, n = len(text1), len(text2) dp = [[0] * (n + 1) for _ inrange(m + 1)] for i inrange(1, m + 1): for j inrange(1, n + 1): if text1[i - 1] == text2[j - 1]: dp[i][j] = dp[i - 1][j - 1] + 1 else: dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]) return dp[-1][-1]
Given an array A of integers, return the length of the longest arithmetic subsequence in A. Recall that a subsequence of A is a list A[i_1], A[i_2], …, A[i_k] with 0 <= i_1 < i_2 < … < i_k <= A.length - 1, and that a sequence B is arithmetic if B[i+1] - B[i] are all the same value (for 0 <= i < B.length - 1).
Example 1: Input: [3,6,9,12] Output: 4 Explanation: The whole array is an arithmetic sequence with steps of length = 3.
Example 2: Input: [9,4,7,2,10] Output: 3 Explanation: The longest arithmetic subsequence is [4,7,10].
Example 3: Input: [20,1,15,3,10,5,8] Output: 4 Explanation: The longest arithmetic subsequence is [20,15,10,5].
Constraints: m == matrix.length n == matrix[i].length 1 <= m, n <= 300 matrix[i][j] is '0' or '1'.
暴力:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution: defmaximalSquare(self, matrix: List[List[str]]) -> int: m, n = len(matrix), len(matrix[0]) ans = 0 for r inrange(m): for c inrange(n): if matrix[r][c] == "1": tr, tc = r, c cur = 1 while tr < m - 1and tc < n - 1: tr += 1 tc += 1 ifall(matrix[tr][nc] == '1'for nc inrange(c, tc + 1)) andall(matrix[nr][tc] == '1'for nr inrange(r, tr + 1)): cur += 1 else: break ans = max(ans, cur) return ans * ans
DP space: O(m*n):
1 2 3 4 5 6 7 8 9 10 11
classSolution: defmaximalSquare(self, matrix: List[List[str]]) -> int: m, n = len(matrix), len(matrix[0]) ans = 0 f = [[0] * (n + 1) for _ inrange(m + 1)] for r inrange(m): for c inrange(n): if matrix[r][c] == "1": f[r + 1][c + 1] = min(f[r][c], f[r + 1][c], f[r][c + 1]) + 1 ans = max(ans, f[r + 1][c + 1]) return ans * ans
DP space: O(n):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defmaximalSquare(self, matrix: List[List[str]]) -> int: m, n = len(matrix), len(matrix[0]) ans = pre = 0 f = [0] * (n + 1) for r inrange(m): for c inrange(n): tmp = f[c + 1] if matrix[r][c] == "1": f[c + 1] = min(f[c], f[c + 1], pre) + 1 ans = max(ans, f[c + 1]) pre = tmp else: f[c + 1] = 0 return ans * ans
You are given coins of different denominations and a total amount of money amount. Write a function to compute the fewest number of coins that you need to make up that amount. If that amount of money cannot be made up by any combination of the coins, return -1.
In the computer world, use restricted resource you have to generate maximum benefit is what we always want to pursue. For now, suppose you are a dominator of m 0s and n 1s respectively. On the other hand, there is an array with strings consisting of only 0s and 1s. Now your task is to find the maximum number of strings that you can form with given m 0s and n 1s. Each 0 and 1 can be used at most once. Note: The given numbers of 0s and 1s will both not exceed 100 The size of given string array won’t exceed 600.
Example 1: Input: Array = {“10”, “0001”, “111001”, “1”, “0”}, m = 5, n = 3 Output: 4 Explanation: This are totally 4 strings can be formed by the using of 5 0s and 3 1s, which are “10,”0001”,”1”,”0”
Example 2: Input: Array = {“10”, “0”, “1”}, m = 1, n = 1 Output: 2 Explanation: You could form “10”, but then you’d have nothing left. Better form “0” and “1”. Bruteforce:
1 2 3 4 5 6 7 8 9 10 11 12
classSolution: deffindMaxForm(self, strs: List[str], m: int, n: int) -> int: return self.helper(strs, m, n, 0, collections.defaultdict(dict)) defhelper(self, strs, m, n, idx, memo): if m in memo and n in memo[m] and idx in memo[m][n]: return memo[m][n][idx] memo.setdefault(m, {}).setdefault(n, {})[idx] = 0 for i inrange(idx, len(strs)): zeros, ones = strs[i].count('0'), strs[i].count('1') if zeros <= m and ones <= n: memo[m][n][idx] = max(memo[m][n][idx], self.helper(strs, m - zeros, n - ones, i + 1, memo) + 1) return memo[m][n][idx]
DP:
1 2 3 4 5 6 7 8 9 10 11 12
classSolution: deffindMaxForm(self, strs: List[str], m: int, n: int) -> int: dp = [[[0] * (n + 1) for _ inrange(m + 1)] for _ inrange(len(strs) + 1)] for i inrange(1, len(strs) + 1): zeros, ones = strs[i - 1].count('0'), strs[i - 1].count('1') for j inrange(m + 1): for k inrange(n + 1): if j >= zeros and k >= ones: dp[i][j][k] = max(dp[i - 1][j][k], dp[i - 1][j - zeros][k - ones] + 1) else: dp[i][j][k] = dp[i - 1][j][k] return dp[-1][-1][-1]
Given a non-empty array containing only positive integers, find if the array can be partitioned into two subsets such that the sum of elements in both subsets is equal.
Note: Each of the array element will not exceed 100. The array size will not exceed 200.
Example 1: Input: [1, 5, 11, 5] Output: true Explanation: The array can be partitioned as [1, 5, 5] and [11].
Example 2: Input: [1, 2, 3, 5] Output: false Explanation: The array cannot be partitioned into equal sum subsets.
Roman numerals are represented by seven different symbols: I, V, X, L, C, D and M.
Symbol Value I 1 V 5 X 10 L 50 C 100 D 500 M 1000 For example, two is written as II in Roman numeral, just two one's added together. Twelve is written as, XII, which is simply X + II. The number twenty seven is written as XXVII, which is XX + V + II.
Roman numerals are usually written largest to smallest from left to right. However, the numeral for four is not IIII. Instead, the number four is written as IV. Because the one is before the five we subtract it making four. The same principle applies to the number nine, which is written as IX. There are six instances where subtraction is used:
I can be placed before V (5) and X (10) to make 4 and 9. X can be placed before L (50) and C (100) to make 40 and 90. C can be placed before D (500) and M (1000) to make 400 and 900. Given a roman numeral, convert it to an integer. Input is guaranteed to be within the range from 1 to 3999.
Example 1:
Input: "III" Output: 3 Example 2:
Input: "IV" Output: 4 Example 3:
Input: "IX" Output: 9 Example 4:
Input: "LVIII" Output: 58 Explanation: L = 50, V= 5, III = 3. Example 5:
Input: "MCMXCIV" Output: 1994 Explanation: M = 1000, CM = 900, XC = 90 and IV = 4.
遍历:
1 2 3 4 5 6 7 8 9 10 11 12
classSolution: defromanToInt(self, s: str) -> int: d = {'I': 1, 'V': 5, 'X': 10, 'L': 50, 'C': 100, 'D': 500,'M': 1000} ans = 0 i = 0 while i < len(s): if i < len(s) - 1and d[s[i]] < d[s[i + 1]]: ans -= d[s[i]] else: ans += d[s[i]] i += 1 return ans
递归:
1 2 3 4 5 6 7 8 9 10 11 12
classSolution: defromanToInt(self, s: str) -> int: d = {'I': 1, 'V': 5, 'X': 10, 'L': 50, 'C': 100, 'D': 500,'M': 1000} ifnot s: return0 iflen(s) == 1: return d[s] first, second = d[s[0]], d[s[1]] if first < second: return second - first + self.romanToInt(s[2:]) else: return first + self.romanToInt(s[1:])
-100.0 < x < 100.0 n is a 32-bit signed integer, within the range [−231, 231 − 1]
1 2 3 4 5 6 7 8
classSolution: defmyPow(self, x: float, n: int) -> float: defhelper(x, n): if n == 0: return1 res = helper(x, n // 2) return res * res if n % 2 == 0else x * res * res return helper(x, n) if n > 0else1 / helper(x, -n)
Both dividend and divisor will be 32-bit signed integers. The divisor will never be 0. Assume we are dealing with an environment which could only store integers within the 32-bit signed integer range: [−231, 231 − 1]. For the purpose of this problem, assume that your function returns 231 − 1 when the division result overflows.
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: defdivide(self, dividend: int, divisor: int) -> int: sign = 1if (dividend > 0) == (divisor > 0) else -1 dividend, divisor = abs(dividend), abs(divisor) res = 0 while dividend >= divisor: t, i = divisor, 1 while dividend >= t: dividend -= t res += i t <<= 1 i <<= 1 returnmin(max(res * sign, -2 ** 31), 2 ** 31 - 1)
The gray code is a binary numeral system where two successive values differ in only one bit.
Given a non-negative integer n representing the total number of bits in the code, print the sequence of gray code. A gray code sequence must begin with 0.
For a given n, a gray code sequence may not be uniquely defined. For example, [0,2,3,1] is also a valid gray code sequence.
00 - 0 10 - 2 11 - 3 01 - 1 Example 2:
Input: 0 Output: [0] Explanation: We define the gray code sequence to begin with 0. A gray code sequence of n has size = 2n, which for n = 0 the size is 20 = 1. Therefore, for n = 0 the gray code sequence is [0].
1 2 3 4 5 6
classSolution: defgrayCode(self, n: int) -> List[int]: ans = [0] for i inrange(n): ans += [x + pow(2, i) for x inreversed(ans)] return ans
Note: It is intended for the problem statement to be ambiguous. You should gather all requirements up front before implementing one. However, here is a list of characters that can be in a valid decimal number: Numbers 0-9 Exponent - “e” Positive/negative sign - “+”/“-“ Decimal point - “.” Of course, the context of these characters also matters in the input.
public class Foo { public void first() { print("first"); } public void second() { print("second"); } public void third() { print("third"); } }
The same instance of Foo will be passed to three different threads. Thread A will call first(), thread B will call second(), and thread C will call third(). Design a mechanism and modify the program to ensure that second() is executed after first(), and third() is executed after second().
1 2 3 4 5 6 7 8 9
Example 1: Input: [1,2,3] Output: "firstsecondthird" Explanation: There are three threads being fired asynchronously. The input [1,2,3] means thread A calls first(), thread B calls second(), and thread C calls third(). "firstsecondthird" is the correct output.
Example 2: Input: [1,3,2] Output: "firstsecondthird" Explanation: The input [1,3,2] means thread A calls first(), thread B calls third(), and thread C calls second(). "firstsecondthird" is the correct output.
Note: We do not know how the threads will be scheduled in the operating system, even though the numbers in the input seems to imply the ordering. The input format you see is mainly to ensure our tests’ comprehensiveness.
class FooBar { public void foo() { for (int i = 0; i < n; i++) { print("foo"); } } public void bar() { for (int i = 0; i < n; i++) { print("bar"); } } }
The same instance of FooBar will be passed to two different threads. Thread A will call foo() while thread B will call bar(). Modify the given program to output “foobar” n times.
1 2 3 4 5 6 7 8 9
Example 1: Input: n = 1 Output: "foobar" Explanation: There are two threads being fired asynchronously. One of them calls foo(), while the other calls bar(). "foobar" is being output 1 time.
Example 2: Input: n = 2 Output: "foobarfoobar" Explanation: "foobar" is being output 2 times.
class ZeroEvenOdd { public ZeroEvenOdd(int n) { ... } // constructor public void zero(printNumber) { ... } // only output 0's public void even(printNumber) { ... } // only output even numbers public void odd(printNumber) { ... } // only output odd numbers }
The same instance of ZeroEvenOdd will be passed to three different threads: Thread A will call zero() which should only output 0’s. Thread B will call even() which should only ouput even numbers. Thread C will call odd() which should only output odd numbers. Each of the threads is given a printNumber method to output an integer. Modify the given program to output the series 010203040506… where the length of the series must be 2n.
Example 1: Input: n = 2 Output: “0102” Explanation: There are three threads being fired asynchronously. One of them calls zero(), the other calls even(), and the last one calls odd(). “0102” is the correct output.
There are two kinds of threads, oxygen and hydrogen. Your goal is to group these threads to form water molecules. There is a barrier where each thread has to wait until a complete molecule can be formed. Hydrogen and oxygen threads will be given releaseHydrogen and releaseOxygen methods respectively, which will allow them to pass the barrier. These threads should pass the barrier in groups of three, and they must be able to immediately bond with each other to form a water molecule. You must guarantee that all the threads from one molecule bond before any other threads from the next molecule do.
In other words: If an oxygen thread arrives at the barrier when no hydrogen threads are present, it has to wait for two hydrogen threads. If a hydrogen thread arrives at the barrier when no other threads are present, it has to wait for an oxygen thread and another hydrogen thread. We don’t have to worry about matching the threads up explicitly; that is, the threads do not necessarily know which other threads they are paired up with. The key is just that threads pass the barrier in complete sets; thus, if we examine the sequence of threads that bond and divide them into groups of three, each group should contain one oxygen and two hydrogen threads.
Write synchronization code for oxygen and hydrogen molecules that enforces these constraints.
Example 1: Input: “HOH” Output: “HHO” Explanation: “HOH” and “OHH” are also valid answers.
Example 2: Input: “OOHHHH” Output: “HHOHHO” Explanation: “HOHHHO”, “OHHHHO”, “HHOHOH”, “HOHHOH”, “OHHHOH”, “HHOOHH”, “HOHOHH” and “OHHOHH” are also valid answers.
Constraints: Total length of input string will be 3n, where 1 ≤ n ≤ 20. Total number of H will be 2n in the input string. Total number of O will be n in the input string.
Given a 32-bit signed integer, reverse digits of an integer.
Example 1:
Input: 123 Output: 321 Example 2:
Input: -123 Output: -321 Example 3:
Input: 120 Output: 21 Note: Assume we are dealing with an environment which could only store integers within the 32-bit signed integer range: [−231, 231 − 1]. For the purpose of this problem, assume that your function returns 0 when the reversed integer overflows.
高频
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution: defreverse(self, x: int) -> int: if x == 0: return0 if x > 0: sign = 1 else: sign = -1 x = -x ans = 0 while x: ans = ans * 10 + x % 10 x //= 10 if (sign == 1and ans > pow(2, 31) - 1) or (sign == -1and ans > pow(2, 31)): return0 return sign * ans
总结:…while x:…ans = ans * 10 + x % 10。转成字符串[::-1]是更优解
classSolution: defnextPermutation(self, nums: List[int]) -> None: n = len(nums) #find pivot pivot = -1 for i inrange(n - 1, 0, -1): if nums[i - 1] < nums[i]: pivot = i - 1 break defreverse(l, r): while l < r: nums[l], nums[r] = nums[r], nums[l] l += 1 r -= 1 if pivot == -1: reverse(0, n - 1) return #find rightmost > element in surfix and swap for i inrange(n - 1, pivot, -1): if nums[i] > nums[pivot]: rightmostI = i break nums[pivot], nums[rightmostI] = nums[rightmostI], nums[pivot] #reverse surfix reverse(pivot + 1, n - 1)
Given an array nums of n integers where n > 1, return an array output such that output[i] is equal to the product of all the elements of nums except nums[i].
Example: Input: [1,2,3,4] Output: [24,12,8,6] Note: Please solve it without division and in O(n).
Follow up: Could you solve it with constant space complexity? (The output array does not count as extra space for the purpose of space complexity analysis.)
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: defproductExceptSelf(self, nums: List[int]) -> List[int]: p = 1 n = len(nums) ans = [0] * n for i inrange(n): ans[i] = p p *= nums[i] p = 1 for i inrange(n - 1, -1, -1): ans[i] *= p p *= nums[i] return ans
Given n non-negative integers representing the histogram’s bar height where the width of each bar is 1, find the area of largest rectangle in the histogram. Above is a histogram where width of each bar is 1, given height = [2,1,5,6,2,3]. The largest rectangle is shown in the shaded area, which has area = 10 unit.
Given n non-negative integers representing an elevation map where the width of each bar is 1, compute how much water it is able to trap after raining. The above elevation map is represented by array [0,1,0,2,1,0,1,3,2,1,2,1]. In this case, 6 units of rain water (blue section) are being trapped. Thanks Marcos for contributing this image!
classSolution: deftrap(self, height: List[int]) -> int: n = len(height) maxL = [0] * n maxLSoFar = 0 for i, h inenumerate(height): if h > maxLSoFar: maxLSoFar = h maxL[i] = maxLSoFar maxR = [0] * n maxRSoFar = 0 for i inrange(n - 1, -1, -1): if height[i] > maxRSoFar: maxRSoFar = height[i] maxR[i] = maxRSoFar ans = 0 for i, h inenumerate(height): ans += min(maxL[i], maxR[i]) - h ifmin(maxL[i], maxR[i]) - h else0 return ans
Implement a MyCalendarThree class to store your events. A new event can always be added. Your class will have one method, book(int start, int end). Formally, this represents a booking on the half open interval [start, end), the range of real numbers x such that start <= x < end. A K-booking happens when K events have some non-empty intersection (ie., there is some time that is common to all K events.) For each call to the method MyCalendar.book, return an integer K representing the largest integer such that there exists a K-booking in the calendar. Your class will be called like this: MyCalendarThree cal = new MyCalendarThree(); MyCalendarThree.book(start, end)
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Example 1: MyCalendarThree(); MyCalendarThree.book(10, 20); // returns 1 MyCalendarThree.book(50, 60); // returns 1 MyCalendarThree.book(10, 40); // returns 2 MyCalendarThree.book(5, 15); // returns 3 MyCalendarThree.book(5, 10); // returns 3 MyCalendarThree.book(25, 55); // returns 3 Explanation: The first two events can be booked and are disjoint, so the maximum K-booking is a 1-booking. The third event [10, 40) intersects the first event, and the maximum K-booking is a 2-booking. The remaining events cause the maximum K-booking to be only a 3-booking. Note that the last event locally causes a 2-booking, but the answer is still 3 because eg. [10, 20), [10, 40), and [5, 15) are still triple booked.
Note: The number of calls to MyCalendarThree.book per test case will be at most 400. In calls to MyCalendarThree.book(start, end), start and end are integers in the range [0, 10^9].
1 2 3 4 5 6 7 8 9 10 11 12 13
classMyCalendarThree: def__init__(self): self.meetings = [] defbook(self, start: int, end: int) -> int: from bisect import insort insort(self.meetings, (start, 1)) insort(self.meetings, (end, -1)) cumsum = 0 res = 0 for _, x in self.meetings: cumsum += x res = max(cumsum, res) return res
The count-and-say sequence is a sequence of digit strings defined by the recursive formula:
countAndSay(1) = “1” countAndSay(n) is the way you would “say” the digit string from countAndSay(n-1), which is then converted into a different digit string. To determine how you “say” a digit string, split it into the minimal number of groups so that each group is a contiguous section all of the same character. Then for each group, say the number of characters, then say the character. To convert the saying into a digit string, replace the counts with a number and concatenate every saying.
For example, the saying and conversion for digit string “3322251”: Given a positive integer n, return the nth term of the count-and-say sequence.
Example 1: Input: n = 1 Output: “1” Explanation: This is the base case.
Example 2: Input: n = 4 Output: “1211” Explanation: countAndSay(1) = “1” countAndSay(2) = say “1” = one 1 = “11” countAndSay(3) = say “11” = two 1’s = “21” countAndSay(4) = say “21” = one 2 + one 1 = “12” + “11” = “1211”
Constraints: 1 <= n <= 30
写法1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution: defcountAndSay(self, n: int) -> str: defprocess(): nonlocal ans res = "" i = 0 cnt = 0 while i < len(ans): c = ans[i] while i < len(ans) and ans[i] == c: i += 1 cnt += 1 res += str(cnt) + c cnt = 0 ans = res ans = "1" for _ inrange(n - 1): process() return ans
classSolution: defcountAndSay(self, n: int) -> str: defprocess(): nonlocal ans res = "" num = ans[0] cnt = 0 for c in ans: if c == num: cnt += 1 else: res += str(cnt) + num cnt = 1 num = c res += str(cnt) + num ans = res ans = "1" for _ inrange(n - 1): process() return ans
Each element is either an integer, or a list – whose elements may also be integers or other lists.
Different from the previous question where weight is increasing from root to leaf, now the weight is defined from bottom up. i.e., the leaf level integers have weight 1, and the root level integers have the largest weight.
Example
Example 1: Input: nestedList = [[1,1],2,[1,1]] Output: 8 Explanation: four 1’s at depth 1, one 2 at depth 2
Example 2: Input: nestedList = [1,[4,[6]]] Output: 17 Explanation: one 1 at depth 3, one 4 at depth 2, and one 6 at depth 1; 13 + 42 + 6*1 = 17
classSolution: """ @param nestedList: a list of NestedInteger @return: the sum """ defdepthSumInverse(self, nestedList): deffind_depth(arr, d): nonlocal m_d m_d = max(m_d, d) for it in arr: ifnot it.isInteger(): find_depth(it.getList(), d + 1) m_d = 0 find_depth(nestedList, 1) defw_sum(arr, d): nonlocal ans for it in arr: ifnot it.isInteger(): w_sum(it.getList(), d - 1) else: ans += it.getInteger() * d ans = 0 w_sum(nestedList, m_d) return ans
Given a time represented in the format “HH:MM”, form the next closest time by reusing the current digits. There is no limit on how many times a digit can be reused. You may assume the given input string is always valid. For example, “01:34”, “12:09” are all valid. “1:34”, “12:9” are all invalid.
Example: Given time = “19:34”, return “19:39”. Explanation: The next closest time choosing from digits 1, 9, 3, 4, is 19:39, which occurs 5 minutes later. It is not 19:33, because this occurs 23 hours and 59 minutes later.
Given time = “23:59”, return “22:22”. Explanation: The next closest time choosing from digits 2, 3, 5, 9, is 22:22. It may be assumed that the returned time is next day’s time since it is smaller than the input time numerically.
Explanation: The average value of nodes on level 0 is 3, on level 1 is 14.5, and on level 2 is 11. Hence return [3, 14.5, 11]. Note: The range of node’s value is in the range of 32-bit signed integer.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defaverageOfLevels(self, root: TreeNode) -> List[float]: ifnot root: return [] res = [[]] self.helper(root, res, 0) return [sum(x) / len(x) for x in res] defhelper(self, root, res, depth): ifnot root: return if depth >= len(res): res.append([]) res[depth].append(root.val) self.helper(root.left, res, depth + 1) self.helper(root.right, res, depth + 1)
Linc 900. Closest Binary Search Tree Value (Easy) Given a non-empty binary search tree and a target value, find the value in the BST that is closest to the target. Given target value is a floating point. You are guaranteed to have only one unique value in the BST that is closest to the target.
Example 1: Input: {1} 0.000000 1 Output: [1] Explanation: Binary tree {1}, denote the following structure: 1
Example 2: Input: {3,1,4,#,2} 0.275000 2 Output: [1,2] Explanation: Binary tree {3,1,4,#,2}, denote the following structure: 3 / \ 1 4 \ 2
Challenge Assume that the BST is balanced, could you solve it in less than O(n) runtime (where n = total nodes)?
Notice Given target value is a floating point. You may assume k is always valid, that is: k ≤ total nodes. You are guaranteed to have only one unique set of k values in the BST that are closest to the target.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution: defclosestKValues(self, root, target, k): ans = [] self.helper(root, target, k, ans) return [x[1] for x in ans] defhelper(self, root, target, k, ans): ifnot root: return import heapq heapq.heappush(ans, (-abs(root.val - target), root.val)) iflen(ans) == k + 1: heapq.heappop(ans) self.helper(root.left, target, k, ans) self.helper(root.right, target, k, ans)
classSolution: deffindTarget(self, root: TreeNode, k: int) -> bool: ifnot root: returnFalse seen = set() return self.helper(root, k, seen) defhelper(self, root, k, seen): ifnot root: returnFalse if k - root.val in seen: returnTrue seen.add(root.val) return self.helper(root.left, k, seen) or self.helper(root.right, k, seen)
遍历BFS:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: deffindTarget(self, root: TreeNode, k: int) -> bool: q = [root] seen = set() while q: for _ inrange(len(q)): n = q.pop(0) if k - n.val in seen: returnTrue seen.add(n.val) if n.left: q.append(n.left) if n.right: q.append(n.right) returnFalse
Print a binary tree in an m*n 2D string array following these rules:
The row number m should be equal to the height of the given binary tree.
The column number n should always be an odd number.
The root node’s value (in string format) should be put in the exactly middle of the first row it can be put. The column and the row where the root node belongs will separate the rest space into two parts (left-bottom part and right-bottom part). You should print the left subtree in the left-bottom part and print the right subtree in the right-bottom part. The left-bottom part and the right-bottom part should have the same size. Even if one subtree is none while the other is not, you don’t need to print anything for the none subtree but still need to leave the space as large as that for the other subtree. However, if two subtrees are none, then you don’t need to leave space for both of them.
Each unused space should contain an empty string “”.
Given the root node of a binary search tree (BST) and a value to be inserted into the tree, insert the value into the BST. Return the root node of the BST after the insertion. It is guaranteed that the new value does not exist in the original BST. Note that there may exist multiple valid ways for the insertion, as long as the tree remains a BST after insertion. You can return any of them.
For example, Given the tree: 4 / \ 2 7 / \ 1 3 And the value to insert: 5 You can return this binary search tree: 4 / \ 2 7 / \ / 1 3 5 This tree is also valid: 5 / \ 2 7 / \ 1 3 \ 4
递归:
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: definsertIntoBST(self, root, val): if val > root.val: if root.right: self.insertIntoBST(root.right, val) else: root.right = TreeNode(val) if val < root.val: if root.left: self.insertIntoBST(root.left, val) else: root.left = TreeNode(val) return root
遍历:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution: definsertIntoBST(self, root, val): n = TreeNode(val) cur = root while cur != n: if n.val > cur.val: ifnot cur.right: cur.right = n cur = cur.right else: ifnot cur.left: cur.left = n cur = cur.left return root
Implement an iterator over a binary search tree (BST). Your iterator will be initialized with the root node of a BST. Calling next() will return the next smallest number in the BST.
Note: next() and hasNext() should run in average O(1) time and uses O(h) memory, where h is the height of the tree. You may assume that next() call will always be valid, that is, there will be at least a next smallest number in the BST when next() is called.
Example 1 Input: {1,-5,11,1,2,4,-2} Output:11 Explanation: The tree is look like this: 1 / \ -5 11 / \ / \ 1 2 4 -2 The average of subtree of 11 is 4.3333, is the maximun.
Example 2 Input: {1,-5,11} Output:11 Explanation: 1 / \ -5 11 The average of subtree of 1,-5,11 is 2.333,-5,11. So the subtree of 11 is the maximun.
Notice LintCode will print the subtree which root is your return node. It’s guaranteed that there is only one subtree with maximum average.
Given a non-empty special binary tree consisting of nodes with the non-negative value, where each node in this tree has exactly two or zero sub-node. If the node has two sub-nodes, then this node’s value is the smaller value among its two sub-nodes. More formally, the property root.val = min(root.left.val, root.right.val) always holds. Given such a binary tree, you need to output the second minimum value in the set made of all the nodes’ value in the whole tree. If no such second minimum value exists, output -1 instead.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
Example 1: Input: 2 / \ 2 5 / \ 5 7 Output: 5 Explanation: The smallest value is 2, the second smallest value is 5.
Example 2: Input: 2 / \ 2 2 Output: -1 Explanation: The smallest value is 2, but there isn't any second smallest value.
Return the root node of a binary search tree that matches the given preorder traversal. (Recall that a binary search tree is a binary tree where for every node, any descendant of node.left has a value < node.val, and any descendant of node.right has a value > node.val. Also recall that a preorder traversal displays the value of the node first, then traverses node.left, then traverses node.right.)
Example 1: Input: [8,5,1,7,10,12] Output: [8,5,10,1,7,null,12]
Note: 1 <= preorder.length <= 100 The values of preorder are distinct.
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: defbstFromPreorder(self, preorder: List[int]) -> TreeNode: ifnot preorder: return root = TreeNode(preorder[0]) iflen(preorder) > 1: rIdxs = [i for i, v inenumerate(preorder) if v > preorder[0]] ifnot rIdxs: root.left = self.bstFromPreorder(preorder[1:]) else: root.left = self.bstFromPreorder(preorder[1:rIdxs[0]]) root.right = self.bstFromPreorder(preorder[rIdxs[0]:]) return root
Given a binary tree, return the vertical order traversal of its nodes values. For each node at position (X, Y), its left and right children respectively will be at positions (X-1, Y-1) and (X+1, Y-1). Running a vertical line from X = -infinity to X = +infinity, whenever the vertical line touches some nodes, we report the values of the nodes in order from top to bottom (decreasing Y coordinates). If two nodes have the same position, then the value of the node that is reported first is the value that is smaller. Return an list of non-empty reports in order of X coordinate. Every report will have a list of values of nodes.
Example 1: Input: [3,9,20,null,null,15,7] Output: [[9],[3,15],[20],[7]] Explanation: Without loss of generality, we can assume the root node is at position (0, 0): Then, the node with value 9 occurs at position (-1, -1); The nodes with values 3 and 15 occur at positions (0, 0) and (0, -2); The node with value 20 occurs at position (1, -1); The node with value 7 occurs at position (2, -2).
Example 2: Input: [1,2,3,4,5,6,7] Output: [[4],[2],[1,5,6],[3],[7]] Explanation: The node with value 5 and the node with value 6 have the same position according to the given scheme. However, in the report “[1,5,6]”, the node value of 5 comes first since 5 is smaller than 6.
Note: The tree will have between 1 and 1000 nodes. Each node’s value will be between 0 and 1000.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution: defverticalTraversal(self, root: TreeNode) -> List[List[int]]: from collections import defaultdict mapping = defaultdict(list) self.helper(root, mapping, 0, 0) print(mapping) res = sorted(mapping.keys(), key = lambda x: -x[1]) res = sorted(res, key = lambda x: x[0]) ans = defaultdict(list) for k in res: ans[k[0]].extend(sorted(mapping[k])) return [ans[k] for k insorted(ans.keys())] defhelper(self, root, mapping, x, y): ifnot root: return mapping[x, y].append(root.val) self.helper(root.left, mapping, x - 1, y - 1) self.helper(root.right, mapping, x + 1, y - 1)
Consider all the leaves of a binary tree. From left to right order, the values of those leaves form a leaf value sequence. For example, in the given tree above, the leaf value sequence is (6, 7, 4, 9, 8). Two binary trees are considered leaf-similar if their leaf value sequence is the same. Return true if and only if the two given trees with head nodes root1 and root2 are leaf-similar.
Note: Both of the given trees will have between 1 and 100 nodes.
We are given a binary tree (with root node root), a target node, and an integer value K. Return a list of the values of all nodes that have a distance K from the target node. The answer can be returned in any order.
Example 1: Input: root = [3,5,1,6,2,0,8,null,null,7,4], target = 5, K = 2 Output: [7,4,1] Explanation: The nodes that are a distance 2 from the target node (with value 5) have values 7, 4, and 1. Note that the inputs “root” and “target” are actually TreeNodes. The descriptions of the inputs above are just serializations of these objects.
Note: The given tree is non-empty. Each node in the tree has unique values 0 <= node.val <= 500. The target node is a node in the tree. 0 <= K <= 1000.
classSolution: defdistanceK(self, root: TreeNode, target: TreeNode, k: int) -> List[int]: defbuild_p(root, pre): ifnot root: return parent[root] = pre build_p(root.left, root) build_p(root.right, root) parent = {} build_p(root, None) seen = {target} q = [(target, 0)] while q: if q[0][1] == k: return [it[0].val for it in q] nq = [] for root, dist in q: for n in (root.left, root.right, parent[root]): if n and n notin seen: seen.add(n) nq.append((n, dist + 1)) q = nq return []
Given an array of integers, 1 ≤ a[i] ≤ n (n = size of array), some elements appear twice and others appear once. Find all the elements that appear twice in this array. Could you do it without extra space and in O(n) runtime?
Example: Input: [4,3,2,7,8,2,3,1] Output: [2,3]
1 2 3 4 5 6 7 8 9
classSolution: deffindDuplicates(self, nums: List[int]) -> List[int]: ans = [] for v in nums: if nums[abs(v) - 1] < 0: ans.append(abs(v)) else: nums[abs(v) - 1] = -nums[abs(v) - 1] return ans
2刷:面经:维萨。O(n) time O(1) space需要flip当前数-1所在的位置的符号,然后检查abs(每个当前数)-1位置是否已为负数
Write an efficient algorithm that searches for a value in an m x n matrix. This matrix has the following properties: Integers in each row are sorted in ascending from left to right. Integers in each column are sorted in ascending from top to bottom.
classSolution: defsearchMatrix(self, matrix, target): ifnot matrix: returnFalse r, c = 0, len(matrix[0]) - 1 while r <= len(matrix) - 1and c >= 0: if target == matrix[r][c]: returnTrue #if target > matrix[r][c] the anser cannot be in the row if target > matrix[r][c]: r += 1 #if target < matrix[r][c] the answer cannot be in the column else: c -= 1 returnFalse
Given two lists of closed intervals, each list of intervals is pairwise disjoint and in sorted order. Return the intersection of these two interval lists. (Formally, a closed interval [a, b] (with a <= b) denotes the set of real numbers x with a <= x <= b. The intersection of two closed intervals is a set of real numbers that is either empty, or can be represented as a closed interval. For example, the intersection of [1, 3] and [2, 4] is [2, 3].)
Example 1: Input: A = [[0,2],[5,10],[13,23],[24,25]], B = [[1,5],[8,12],[15,24],[25,26]] Output: [[1,2],[5,5],[8,10],[15,23],[24,24],[25,25]] Reminder: The inputs and the desired output are lists of Interval objects, and not arrays or lists.
Note: 0 <= A.length < 1000 0 <= B.length < 1000 0 <= A[i].start, A[i].end, B[i].start, B[i].end < 10^9 NOTE: input types have been changed on April 15, 2019. Please reset to default code definition to get new method signature.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution: defintervalIntersection(self, A: List[List[int]], B: List[List[int]]) -> List[List[int]]: ans = [] i, j = 0, 0 while i < len(A) and j < len(B): lo = max(A[i][0], B[j][0]) hi = min(A[i][1], B[j][1]) if lo <= hi: ans.append([lo, hi]) if A[i][1] < B[j][1]: i += 1 else: j += 1 return ans
Design a HashMap without using any built-in hash table libraries.
Implement the MyHashMap class:
MyHashMap() initializes the object with an empty map. void put(int key, int value) inserts a (key, value) pair into the HashMap. If the key already exists in the map, update the corresponding value. int get(int key) returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key. void remove(key) removes the key and its corresponding value if the map contains the mapping for the key.
Explanation MyHashMap myHashMap = new MyHashMap(); myHashMap.put(1, 1); // The map is now [[1,1]] myHashMap.put(2, 2); // The map is now [[1,1], [2,2]] myHashMap.get(1); // return 1, The map is now [[1,1], [2,2]] myHashMap.get(3); // return -1 (i.e., not found), The map is now [[1,1], [2,2]] myHashMap.put(2, 1); // The map is now [[1,1], [2,1]] (i.e., update the existing value) myHashMap.get(2); // return 1, The map is now [[1,1], [2,1]] myHashMap.remove(2); // remove the mapping for 2, The map is now [[1,1]] myHashMap.get(2); // return -1 (i.e., not found), The map is now [[1,1]] Constraints: 0 <= key, value <= 106 At most 104 calls will be made to put, get, and remove.
defput(self, key: int, value: int) -> None: k = key % self.size n = ListNode(key, value) if self.a[k] == None: self.a[k] = n else: c = self.a[k] while c.nextand c.k != key: c = c.next if c.k == key: c.v = value else: c.next = n
defget(self, key: int) -> int: k = key % self.size if self.a[k] == None: return -1 else: c = self.a[k] while c.nextand c.k != key: c = c.next if c.k == key: return c.v return -1
defremove(self, key: int) -> None: k = key % self.size c = self.a[k] if c: pre = c while c.nextand c.k != key: c = c.next pre = c if c.k == key: if pre == c: self.a[k] = None else: pre.next, c.next = c.next, None
Given a non-empty array of integers, return the k most frequent elements.
Example 1: Input: nums = [1,1,1,2,2,3], k = 2 Output: [1,2]
Example 2: Input: nums = [1], k = 1 Output: [1]
Note: You may assume k is always valid, 1 ≤ k ≤ number of unique elements. Your algorithm’s time complexity must be better than O(n log n), where n is the array’s size.
heap O(nlogk), space: O(n)
1 2 3 4 5 6 7 8 9 10 11
classSolution: deftopKFrequent(self, nums: List[int], k: int) -> List[int]: from collections import Counter counter = Counter(nums) import heapq pq = [] for key, v in counter.items(): heapq.heappush(pq, (v, key)) iflen(pq) > k: heapq.heappop(pq) return [key for (v, key) in pq]
classSolution: deftopKFrequent(self, nums: List[int], k: int) -> List[int]: c = Counter(nums) h = list(c.keys()) defqs(l, r): if l < r: p = partition(l, r) if p == n - k: return elif p < n - k: qs(p + 1, r) else: qs(l, p - 1) defpartition(l, r): i = l for j inrange(l, r): if c[h[j]] < c[h[r]]: h[j], h[i] = h[i], h[j] i += 1 h[i], h[r] = h[r], h[i] return i n = len(h) qs(0, n - 1) return h[n - k:]
bucket sort O(n), space: O(n)
1 2 3 4 5 6 7 8 9 10 11
classSolution: deftopKFrequent(self, nums: List[int], k: int) -> List[int]: c = Counter(nums) n = len(nums) b = [[] for _ inrange(n + 1)] for key, v in c.items(): b[v].append(key) ans = [] for i inrange(n, 0, -1): ans.extend(b[i]) return ans[:k]
Given a string s, rearrange the characters of s so that any two adjacent characters are not the same.
Return any possible rearrangement of s or return “” if not possible.
Example 1: Input: s = “aab” Output: “aba”
Example 2: Input: s = “aaab” Output: “”
Constraints: 1 <= s.length <= 500 s consists of lowercase English letters.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution: defreorganizeString(self, s: str) -> str: c = Counter(s) hq = [(-v, k) for k, v in c.items()] heapq.heapify(hq) pre_k, pre_v = '', 0 res = [] while hq: v, k = heapq.heappop(hq) print(hq) res.append(k) if pre_v < 0: heapq.heappush(hq, (pre_v, k)) v += 1 pre_v, pre_k = v, k return''.join(res) iflen(res) == len(s) else''
O(n):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defreorganizeString(self, s: str) -> str: c = Counter(s).most_common() n = len(s) if c[0][1] > (n + 1) // 2: return"" i = 0 ans = [''] * n for k, v in c: for _ inrange(v): ans[i] = k i += 2 if i > n - 1: i = 1 return''.join(ans)
Note: Each element in the result must be unique. The result can be in any order.
1 2 3 4 5 6 7 8 9 10 11
classSolution: defintersection(self, nums1: List[int], nums2: List[int]) -> List[int]: nums1 = set(nums1) nums2 = set(nums2) iflen(nums2) < len(nums1): nums1, nums2 = nums2, nums1 ans = set() for n in nums1: if n in nums2: ans.add(n) return ans
Note: Each element in the result should appear as many times as it shows in both arrays. The result can be in any order.
Follow up: What if the given array is already sorted? How would you optimize your algorithm? What if nums1’s size is small compared to nums2’s size? Which algorithm is better? What if elements of nums2 are stored on disk, and the memory is limited such that you cannot load all elements into the memory at once?
1 2 3 4 5 6 7 8 9 10 11 12
classSolution: defintersect(self, nums1: List[int], nums2: List[int]) -> List[int]: from collections import Counter counter1 = Counter(nums1) counter2 = Counter(nums2) iflen(counter2) > len(counter1): counter1, counter2 = counter2, counter1 ans = [] for k in counter1: if k in counter2: ans.extend([k] * min(counter1[k], counter2[k])) return ans